Product Update | March 2024

What did we ship in March? 🚢
Lots of improvements to evals!
We now allow users to repeat LLM generations and evaluations to get more certainty in evaluation results, we version our custom evaluators, we’ve improved support for large test sets and added search, we now support Mistral models and a new Haystack integration, and our comparison page and global evaluator assignment have been improved.
Got feedback or ideas for the team? Please get in touch
Multi-run evals
You can now re-run a LLM generation and the subsequent evaluation for multiple iterations, to better account for the non-deterministic nature of both phases. Running the generation and evaluation 3, 5, or 7 times and taking a majority result gives you more confidence in an evaluator outcome, and a more granular result to review.
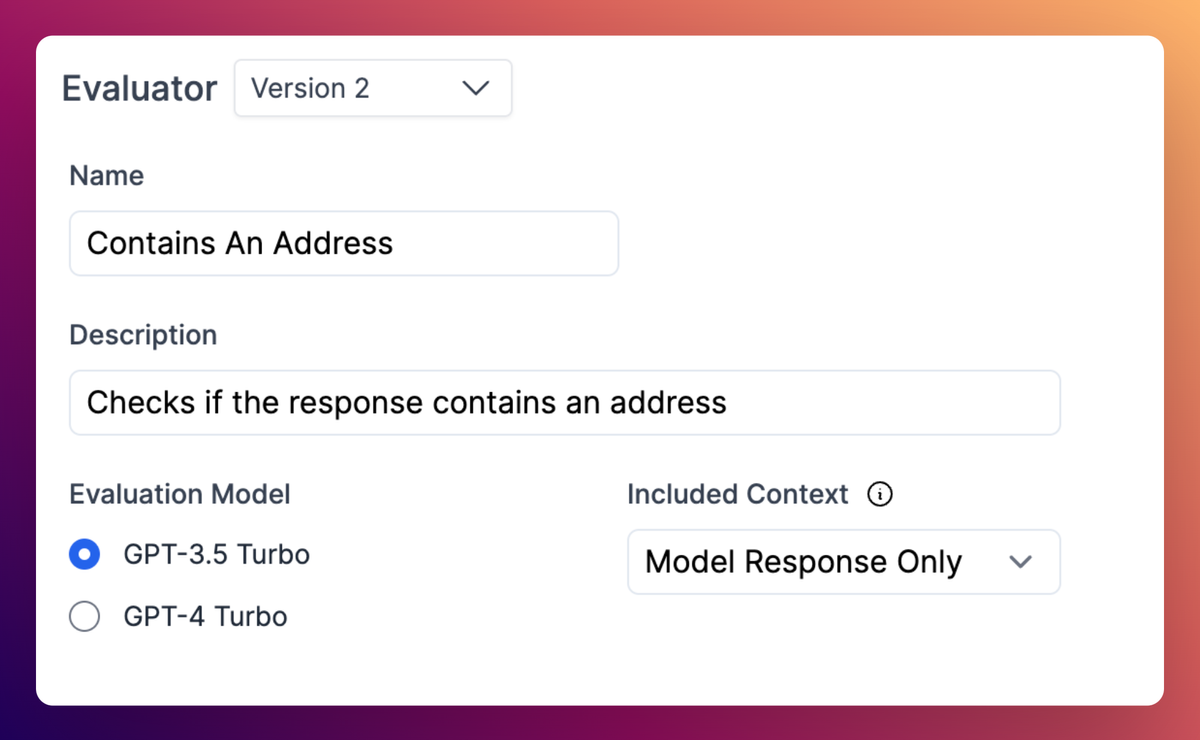
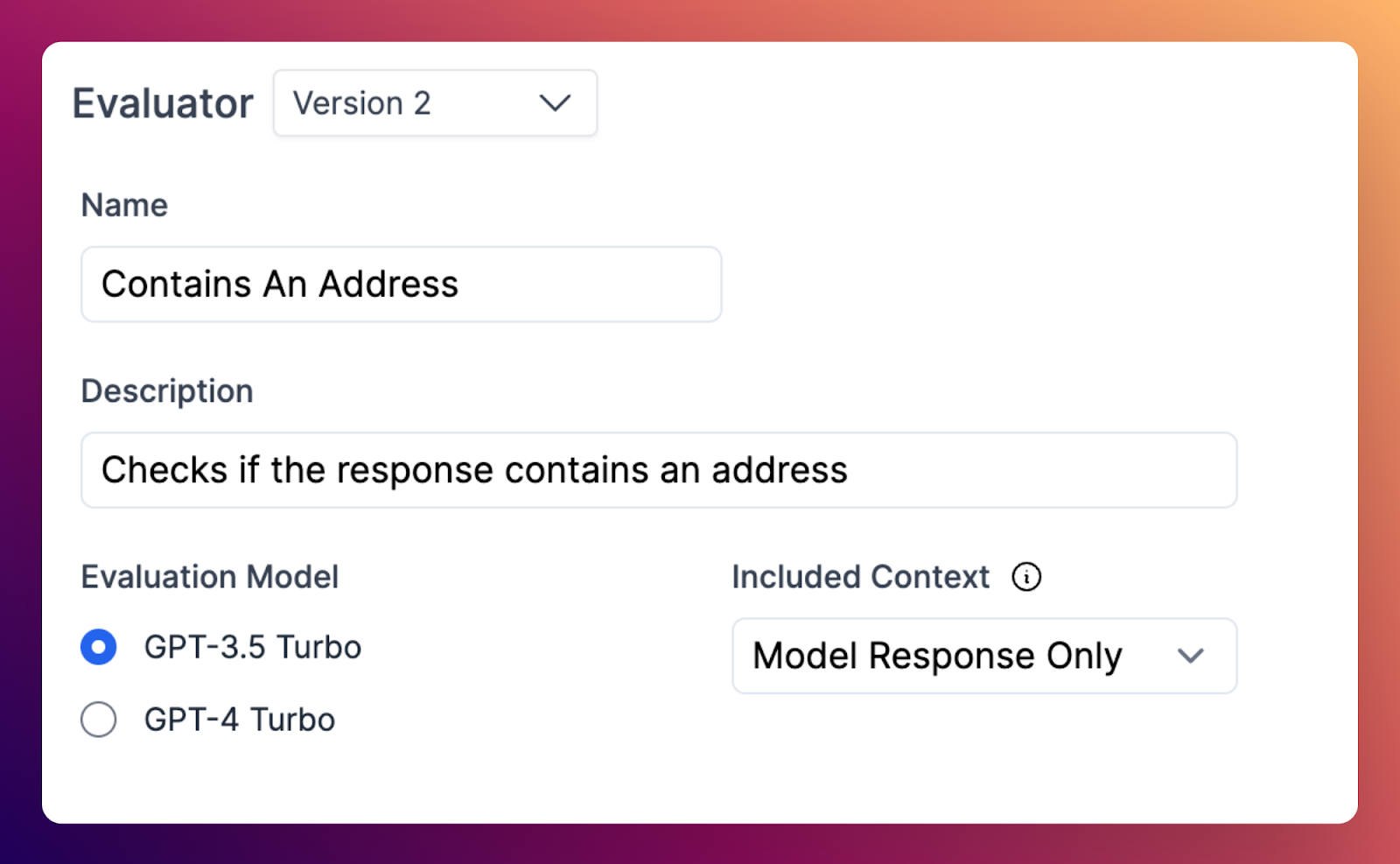
Custom evaluator versioning
Custom evaluators are now versioned! This means you can reference a specific version of the evaluator as you update it, and avoids the challenge of evaluators updating and changing their behavior
Better support for large test sets
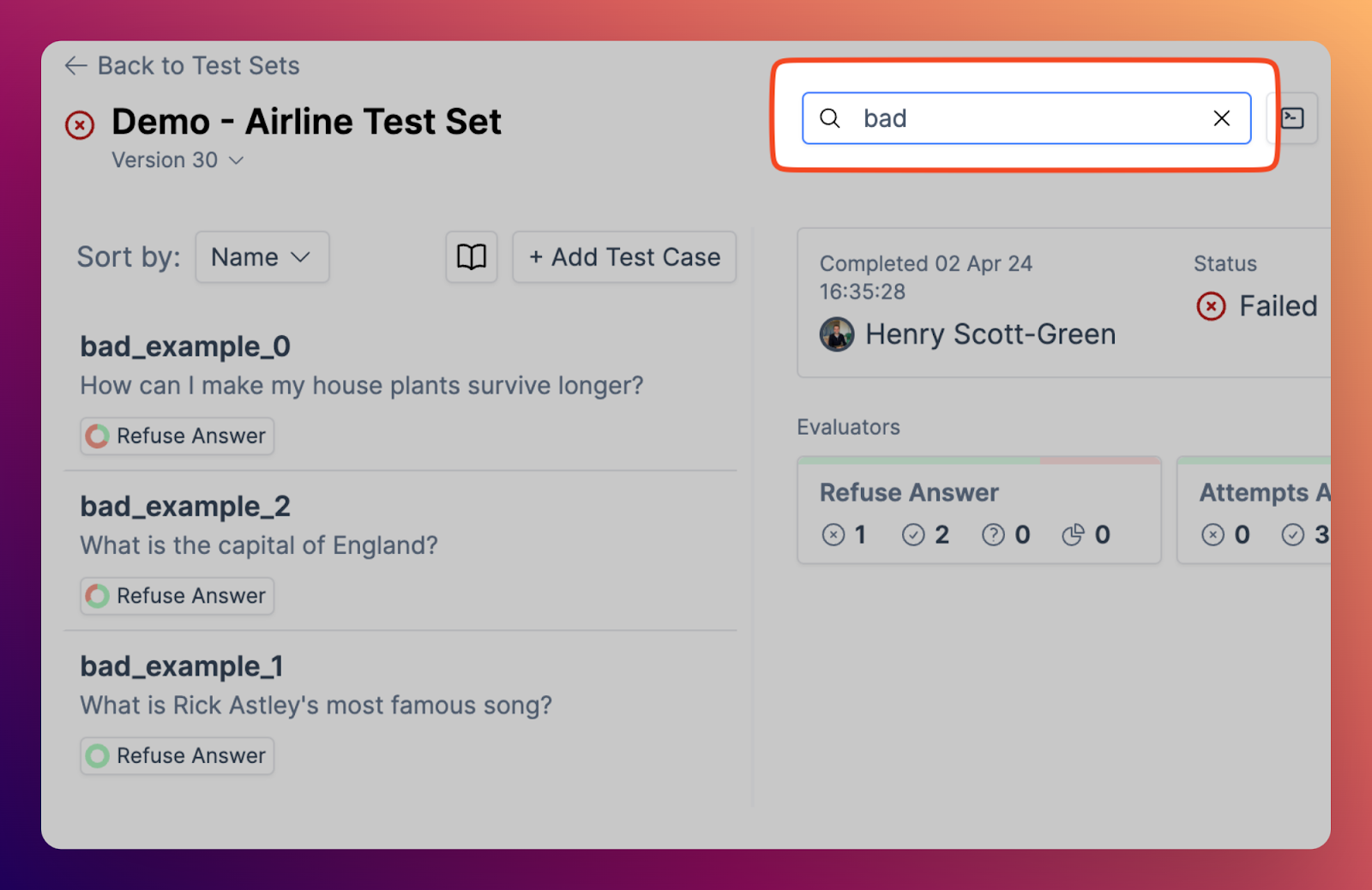
We now have significantly improved support for large test sets with many test cases
Test case search
Related to the above point, we now support searching over all the test cases within a test set. This is helpful for users with large test sets
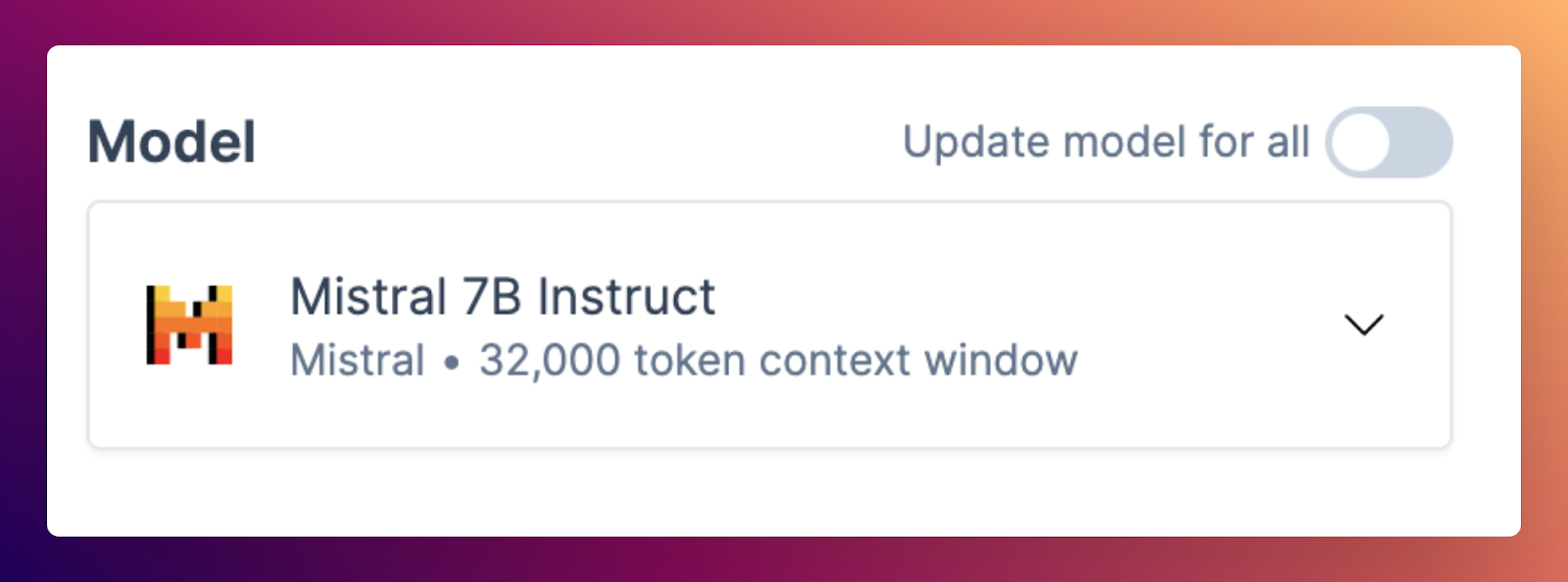
Mistral models
Mistral models Mistral 7B and Mixtral are now supported for generation
Model comparison pages
Model comparison pages have been significantly improved, with better visualizations of the differences between up to four test set versions.

Improved global evaluator assignment
We’ve refreshed the assignment flow for global evaluators, improving the flow to assign an evaluator to every test case within a test set
Haystack integration
We launched our integration with Haystack! This allows users of Haystack to easily log transcripts from Haystack to Context for analysis