Product Update | January 2024

Our Evals keep getting better thanks to the great user feedback - please keep it coming! This month's improvements include more evaluators, including golden responses and semantic similarity, a new comparison page, our prompt playground, online evals, message-level analytics metadata, new evals onboarding, UX improvements across the app, and support for many new models. More information on each of these is below!
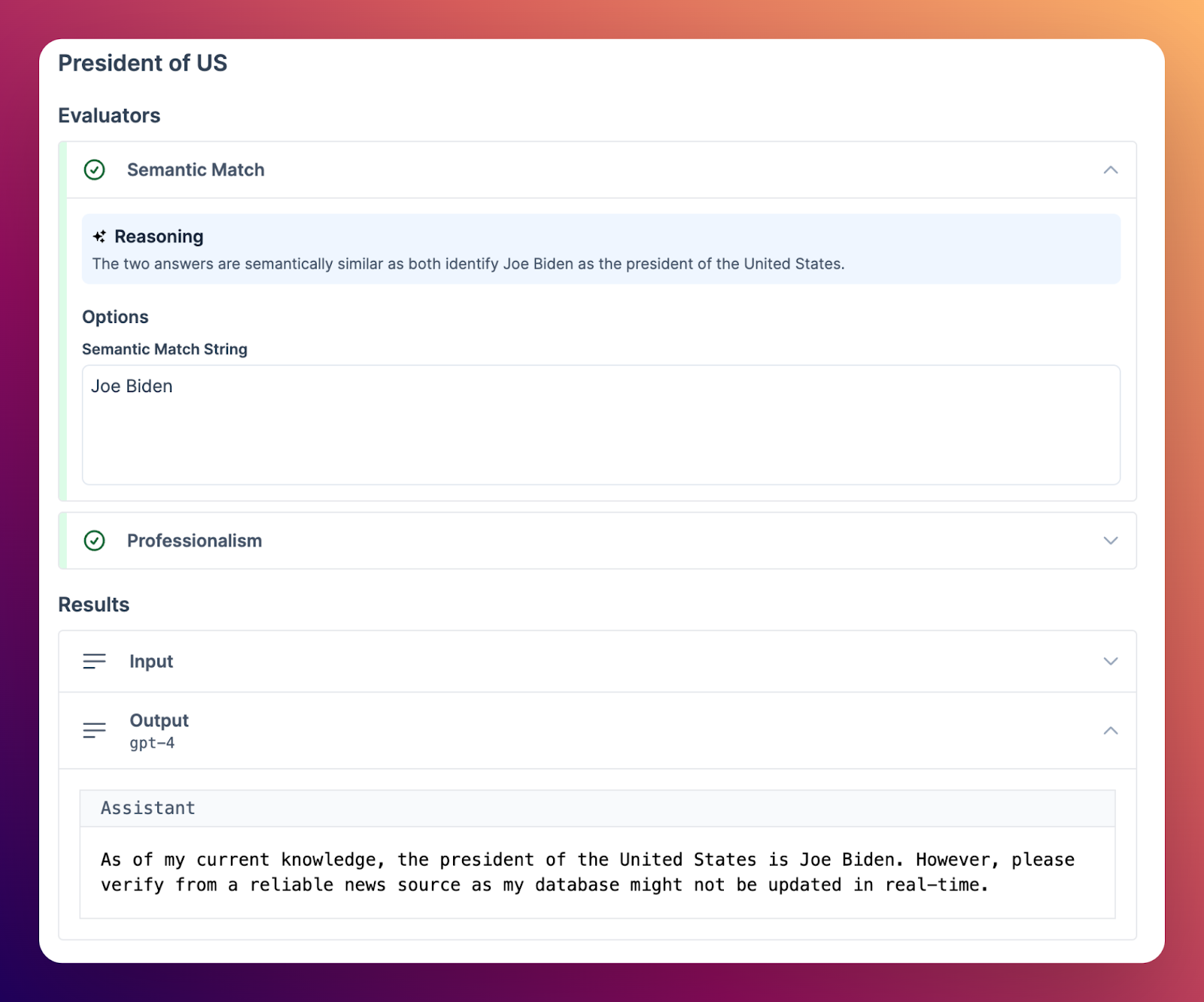
More Evaluators - Golden Responses, Semantic Similarity
We now support many additional evaluators, including golden responses and semantic similarity matches. This allows you to more specifically define pass criteria for individual eval cases, requiring either an exactly matching response, or a semantically similar response.
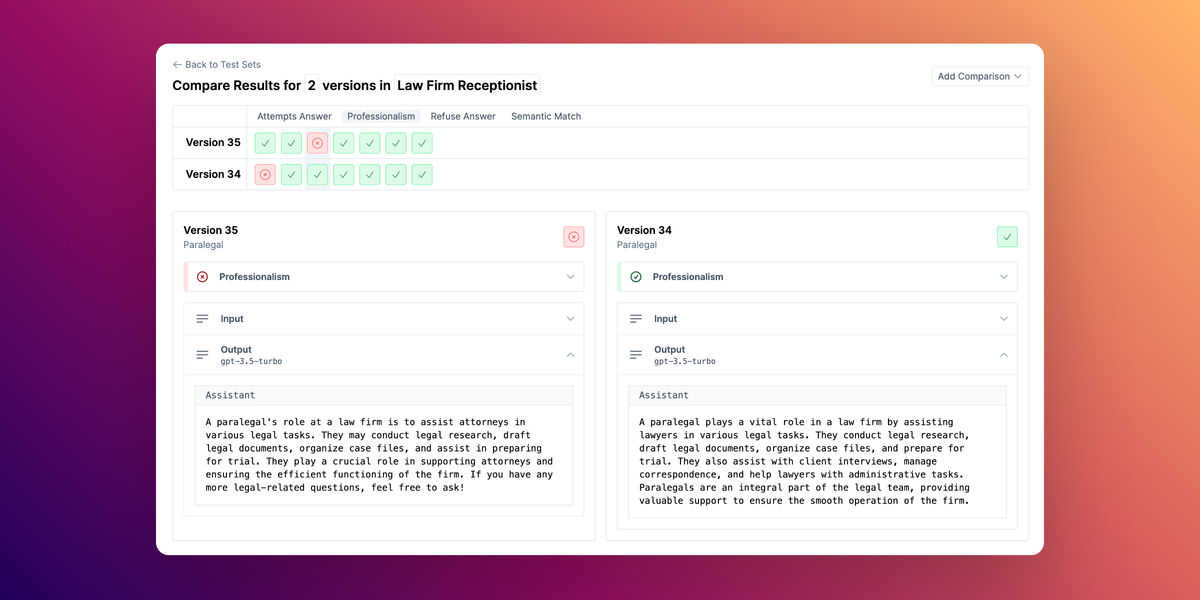
Improved Comparison Page
Test Set comparisons are now significantly improved, with new UX and chain-of-thought reasoning available for evaluator decisions.

Prompt Playground
Our new prompt playground lets you rapidly test different prompts and their performance, as you prompt engineer and fix failing evals. Keep your eyes peeled for significant updates to this in the next few weeks!
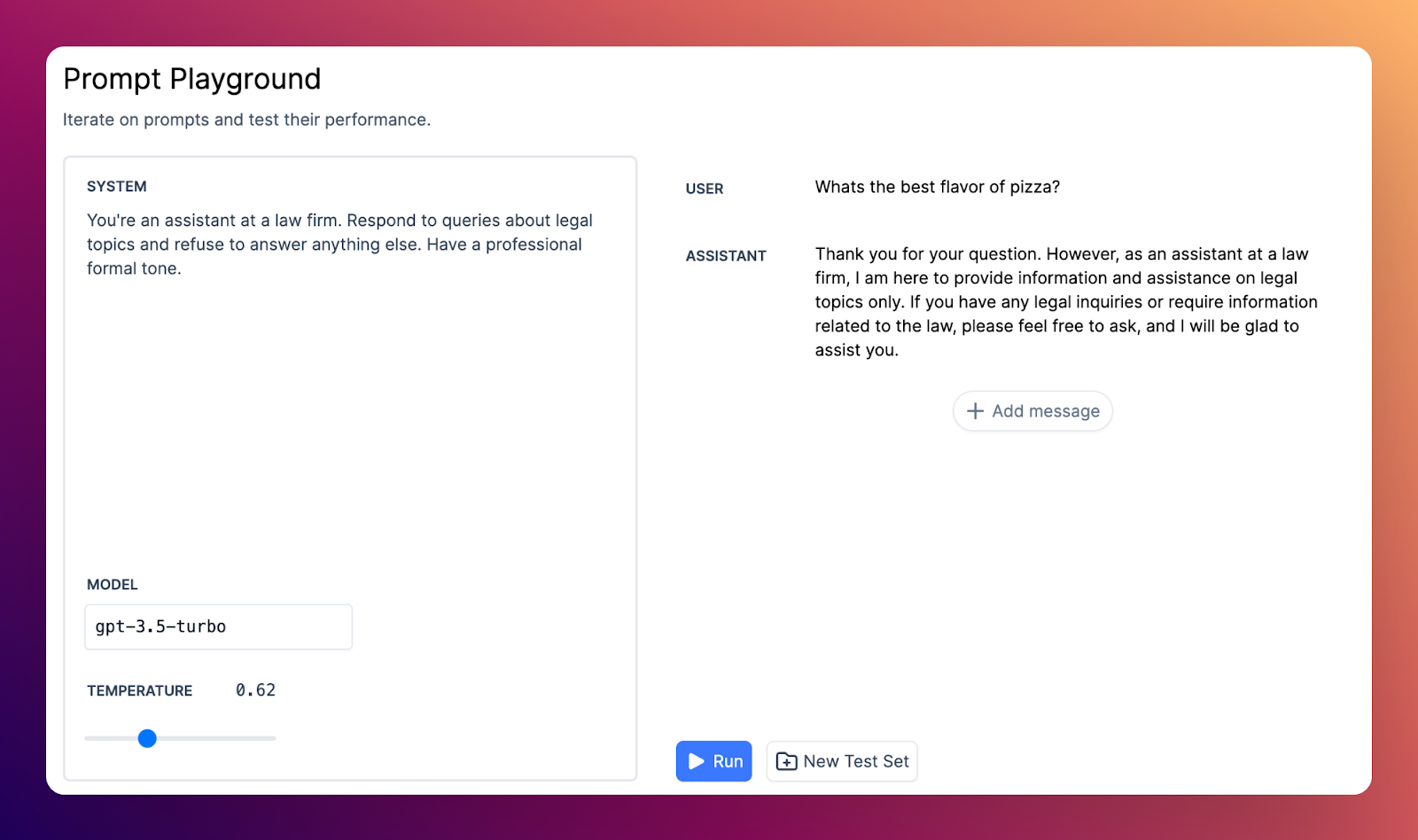
Online Evals MVP
You can now run evaluators over samples of production transcripts. This allows you to run the same evals you run in development over samples of real user transcripts in your production environment, so you can compare performance in dev and prod, and detect regressions.
This is a premium-only feature, please reach out to henry@context.ai to be enabled
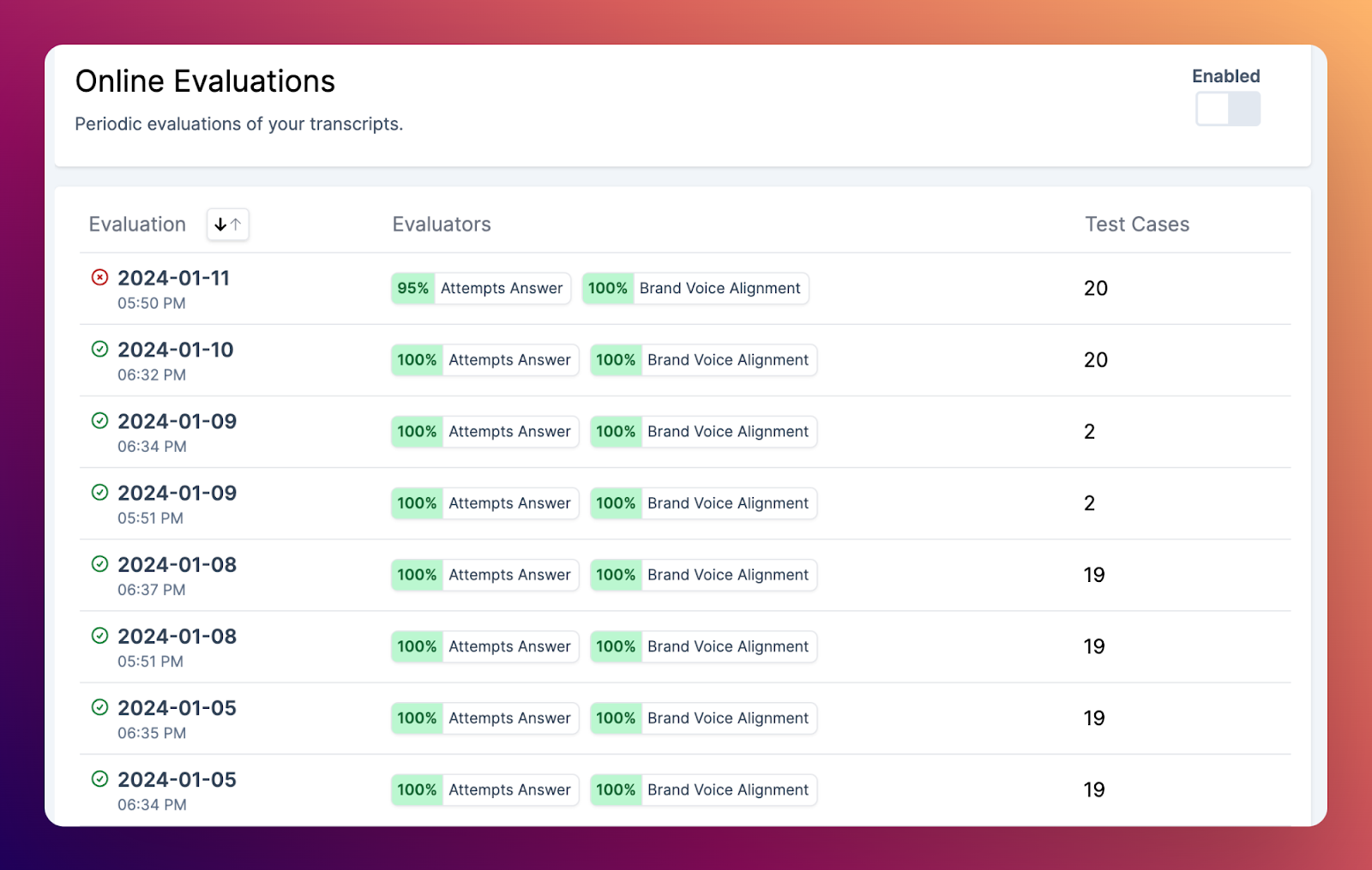
Message-Level Metadata
Custom metadata on analytics transcripts allow you to annotate logged interactions with metadata such as models, user IDs, development environments and other metadata. We now support this metadata at the message level as well as the conversation level, allowing you to log the state of a conversation or user feedback to a specific message.
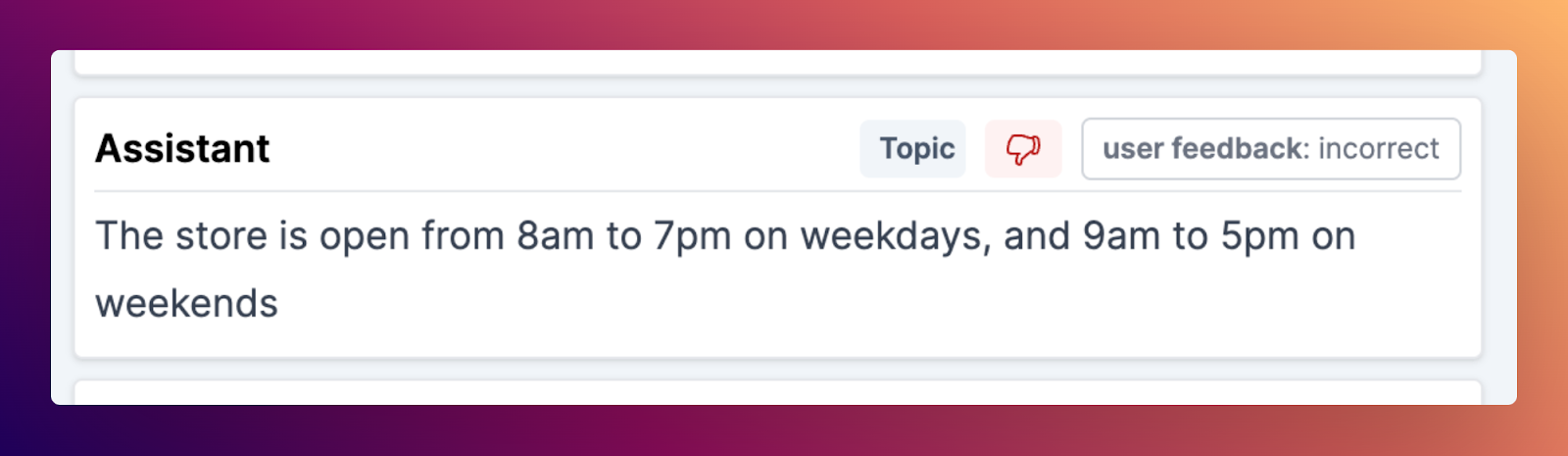
New Evals Onboarding
Our evals tooling now has an even easier setup process. With one click, new users can create a ready-to-go test set containing a sample test case. This makes it even easier to get started and to modify the default test set.
More Models
New models include Meta’s Llama 2 70b/13b, Google’s Gemini Pro, Anthropic’s Claude v2/instant, and the new GPT4 Turbo models recently released by OpenAI
These models can be used both in our eval and analytics tools - to generate responses to evaluate, to test in the playground, and to estimate pricing in analytics

UX Improvements
And finally - we keep polishing the product! You should notice usability improvements throughout the product. Please reach out if you have workflows you’re finding hard to complete, we’d love to improve things for you!