Generative AI Product Problems #1: Accuracy and Hallucinations
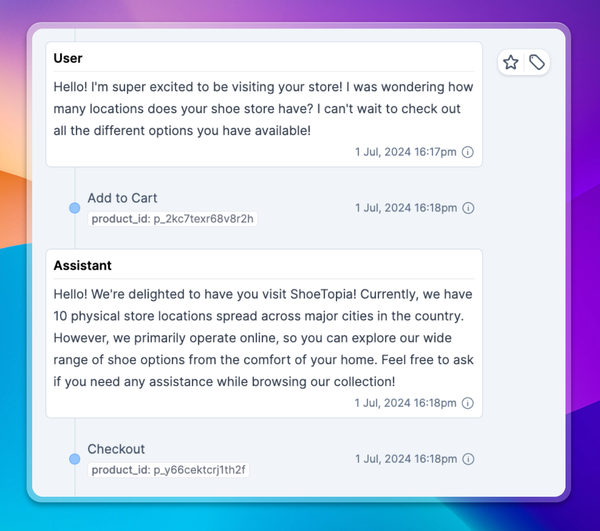
LLMs are notoriously fickle and prone to making up information.

According to ChatGPT, LLMs make up 73.6% of statistics.
Even when hallucinations happen rarely, that’s enough to cast doubt on 100% of an LLM’s responses. Without an easy way to separate fact from fiction, your only option is to be skeptical of everything the model says.
That becomes a hard blocker to deploying an LLM for any serious business application. How are you supposed to trust AI to process insurance claims or handle customer support if it won’t always tell the truth?
Step 1 in solving a problem is to measure it. How your LLM fares against general-purpose benchmarks isn’t that relevant. What really matters is how your product performs for your customers’ use cases.
Track what topics and questions your users are most frequently asking about. If you haven’t launched yet, you can test your LLM offline. If you’ve already launched, check your logs.
Inaccuracies come in many forms:
- Is your LLM incorrectly interpreting users’ inputs?
- Or is it making false assumptions about your business’ offerings?
- Or maybe the model is making promises it can’t keep.
Then, respond accordingly. You might need to try prompt engineering or augmenting your model by linking it to your company’s knowledge base (RAG). Or it could be that you need to implement guardrails for what your LLM can do or say.
Insight into what your users are saying and what your LLM is saying back is the key to building a more reliable AI product. At Context.ai, we’re building the platform to give you that visibility.
To learn more, request a demo at context.ai/demo.