What product experiences are enabled by multi-agent LLM frameworks?


It feels like everyone is excited about multi-agent frameworks - even though their performance isn’t yet ready for prime-time. These performance problems are improving with increasingly powerful models like Claude 3 and GPT-4o - and great things are expected from GPT-5, a launch that will likely make agentic workflows more reliable.
Much has been written about the multi-agent frameworks and how they work - including our comparison of multi-agent frameworks - but the product layer is underexplored. This new technology is only going to deliver value by enabling great product experiences, and as a product manager this is the layer of the stack I find most interesting.
I spoke to a number of developers in the space to understand what they’re building - here are some of the most interesting projects:
Software Development
The most popular use case is agentic software development teams. Developers are using multi-agent frameworks to solve the problems they are most familiar with: building software. This is a great fit for the multi-agent approach, where a team of agents can include a programmer, a planner, and a test developer. Some examples of interesting software development products include:
- AgentCoder is a research project from researchers in London, Hong Kong, and Shanghai. They use a multi-agent framework with a test designer, programmer, and test executor agent to develop software. Software development tasks are often benchmarked on the HumanEval test set, and AgentCoder scored 96.3% compared to GPT-4o with 90.2%
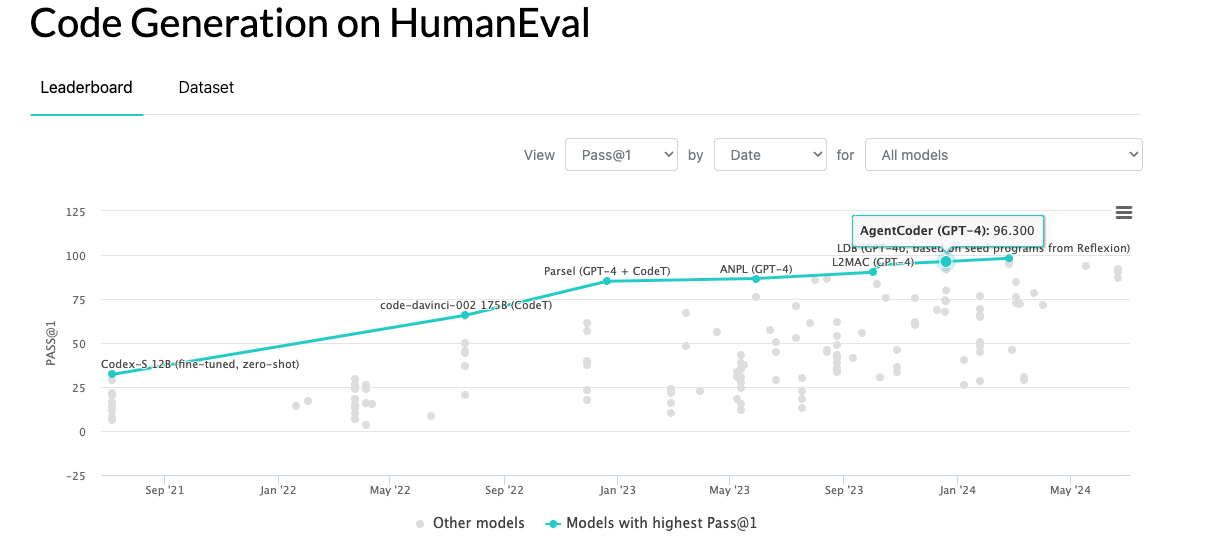
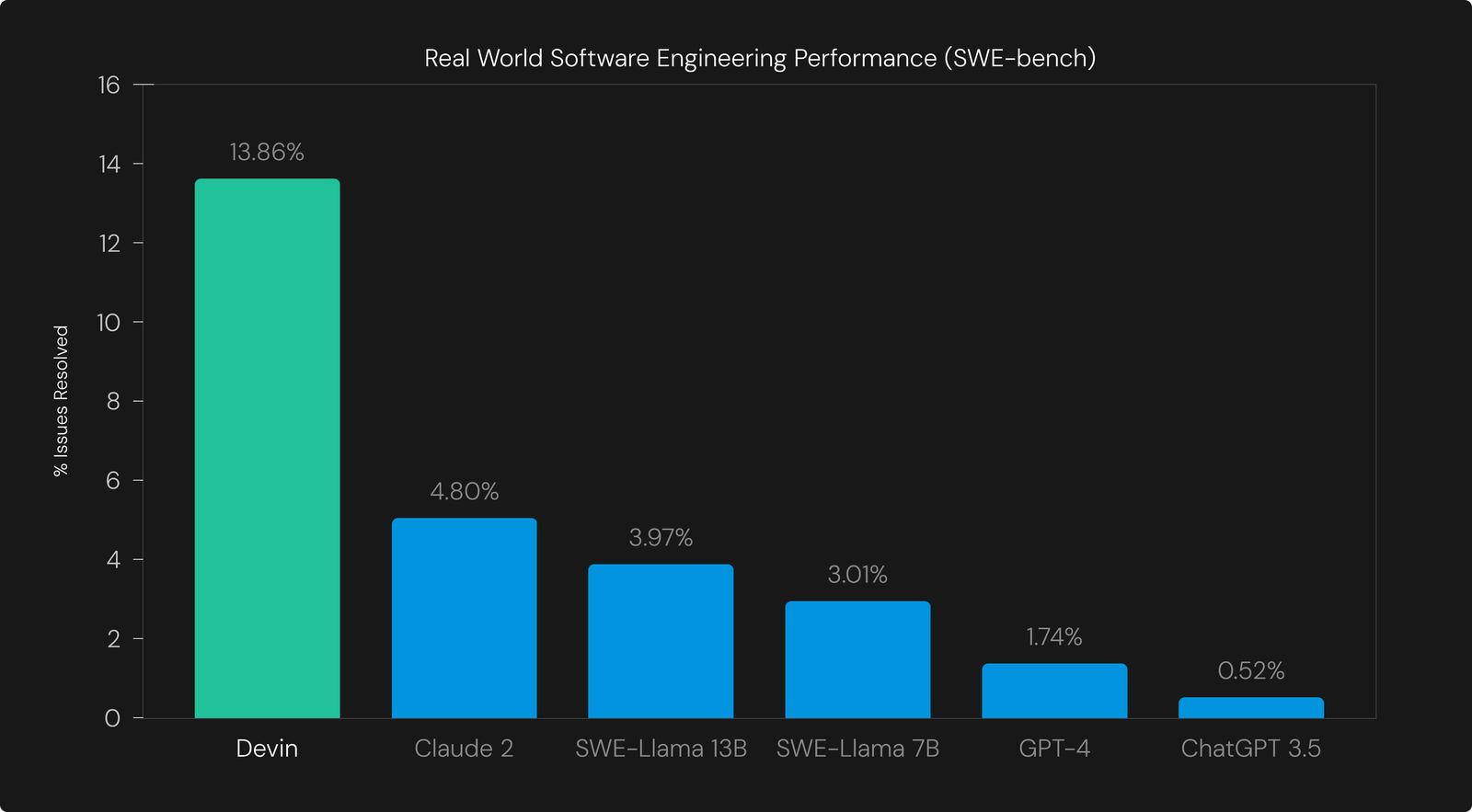
- Devin, from Cognition Labs. Cognition Labs captured a huge amount of attention due to their impressive team and raising at $2B valuation while only 6 months old. The team behind Devin have not shared performance results against the HumanEval benchmark, but their preferred measure of performance is SWE-bench, where the product scored 13.86% vs Claude 2’s 4.80%
Internet Research
LLMs are great at answering questions and teaching users about a topic, but their knowledge is limited. Augmenting their knowledge with RAG is a common technique, but you can go further with multi-agent frameworks. Researcher agents can identify relevant sources in the internet, then summarize these and generate more detailed answers than the model could produce alone.
The most interesting example of this product is GPT Researcher by Tavily AI. This popular product creates detailed reports after completing online research into topics provided by the user. GPT Researcher is built on the LangGraph framework from LangChain. You can see it in action in their demo video. The product uses 7 agents, with the following roles:
- Chief Editor - Oversees the research process and manages the team. This is the "master" agent that coordinates the other agents using Langgraph.
- Researcher (gpt-researcher) - A specialized autonomous agent that conducts in depth research on a given topic.
- Editor - Responsible for planning the research outline and structure.
- Reviewer - Validates the correctness of the research results given a set of criteria.
- Revisor - Revises the research results based on the feedback from the reviewer.
- Writer - Responsible for compiling and writing the final report.
- Publisher - Responsible for publishing the final report in various formats.
More Projects
- Viral Clips New - an open source tool that cuts down long-form video content into shorts for social media
- GPT Newspaper - a tool to create personalized newspapers based on user interest
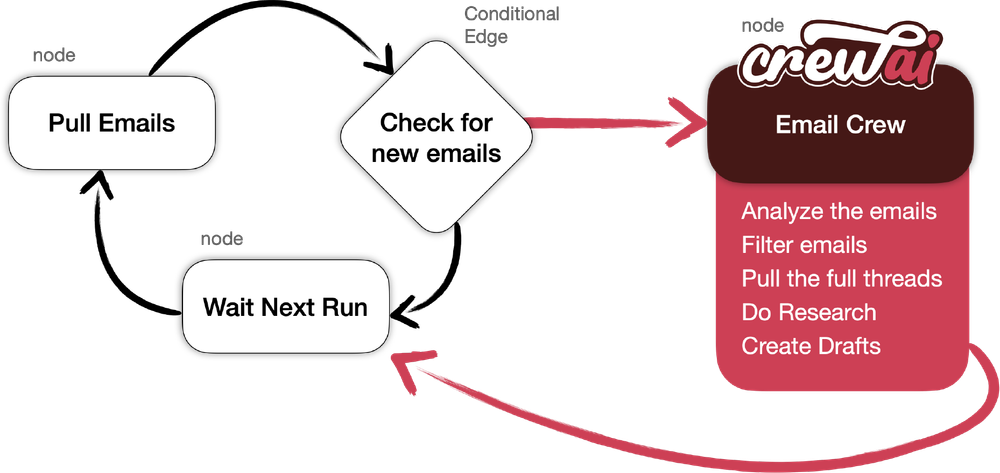
- Email checker by CrewAI - automates the process of checking emails and creating draft responses
More Information
Multi-agent frameworks are still in their infancy, with lots more work needed to bring them into production. If you’re building something interesting in the space we would love to support you with our LLM user analytics platform.