The Product Leader’s Guide to Improving your AI App: Thoughts from an ex-Google PM
AI isn’t just a frontier for engineers. It also presents complex challenges for product leaders. In this post, we’ll walk through the AI product development cycle and show you how to improve user experiences even when they’re highly personalized and rarely identical.
When I joined YouTube’s recommendations team as a product manager, I kept getting the same question: “Why does ‘the algorithm’ need a PM? Isn’t that an engineering problem?”
There’s no doubt that recommending videos at YouTube’s scale is a huge technical challenge. I was lucky to have collaborated with world-class engineers and ML researchers on the cutting edge of the field. That said, it’s also a sophisticated product problem, even if the product largely operates behind the scenes.
Netflix seems to agree and is paying up to $900k for an AI product manager. How does leading an AI product compare to developing conventional software? Fundamentally, there’s no difference—products exist to solve users’ problems, and as product leaders, it’s our job to always advocate for the user.
With AI and especially LLMs, however, the idea of the singular “user” breaks down. AI enables hyper-personalized products, but that also means no two users’ experiences are the same. Although this complicates the product development cycle, you can still stay principled. Let’s walk through how to be an effective product leader for AI applications.
Figure out what to build: Problem first, then solution
The broad strokes of the AI product cycle look the same as any other software development cycle. First and foremost, you’ll be setting the roadmap for what to build.
Resist the temptation to propose features just because they sound cool (a lot of AI products are guilty of this). Instead, start by ideating with a focus on users and their problems. Leverage both qualitative and quantitative sources of information, including user feedback (which hopefully doesn’t go straight into the void!), engagement metrics, etc.
For AI and LLM products in particular, consider the following:
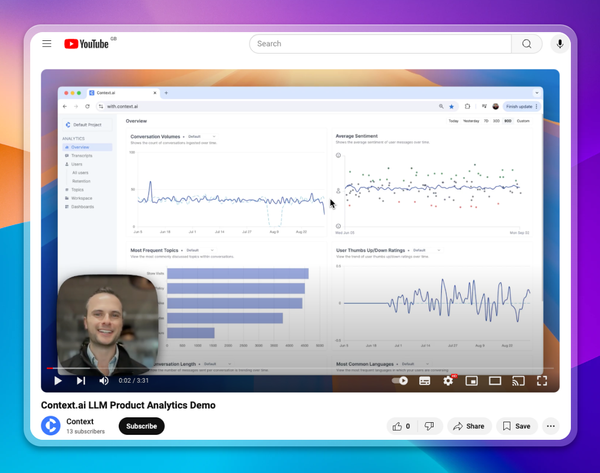
- AI-specific metrics: On top of baseline metrics like DAU and retention, be sure to measure user satisfaction, sentiment, and other indicators of AI model quality. Are users pressing thumbs-up or thumbs-down? Is sentiment (in user-generated messages) positive or negative? Are conversations with AI assistants trending longer over time?
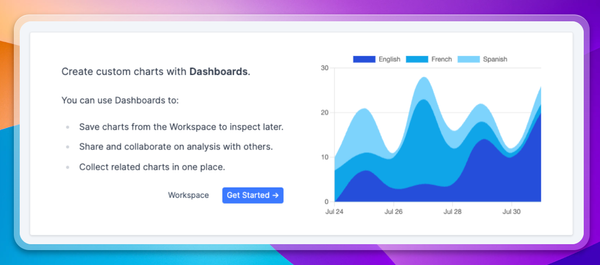
- Data segmentation: Metrics are okay on their own, but they’re really powerful when combined with thoughtful data segmentation. Bucket your users into cohorts according to engagement level or geography to look for patterns. Or try clustering records of user-AI interactions based on topic/intent. Correlating these slices with your metrics can generate actionable insights.
- Transcript analysis: Conversational AI apps have a secret weapon. Users’ message transcripts contain some of the most authentic and comprehensive feedback, without the selection bias of requesting feedback through a form. Of course, user privacy comes first—always sanitize transcripts for PII and seek consent to analyze these records, but with that permission, this is a ripe source of information.
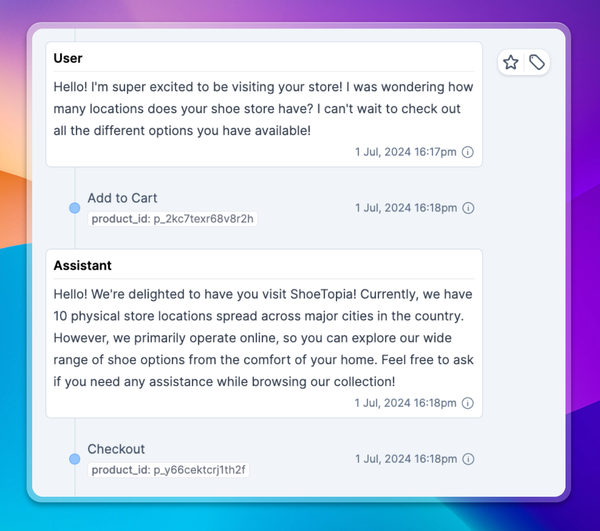
Here’s a practical example of leveraging these techniques for a hypothetical online store’s AI chatbot:
- You refer to your metrics dashboards and notice a spike in negative sentiment.
- You break down the sentiment chart by conversation topic. The negative sentiment is overwhelmingly coming from conversations about product recommendations.
- You filter chat transcripts to inspect the relevant conversations. It turns out your LLM has been hallucinating, recommending products that don’t exist.

Once you’ve identified a problem, don’t immediately try and solve it. Instead, consider the full set of problems your team could work on and prioritize that list—your engineering and design partners will thank you.
As with most other prioritization exercises, you’ll want to estimate some notion of ROI by weighing a feature’s benefits against its implementation cost. Because user experiences are so diverse for AI features, you’ll often need to evaluate a feature’s reach. How many users are experiencing the problem and how severe is it?
After aligning your team on the roadmap, it’s time to execute. While engineering will usually swap into the driver’s seat, product is still very much part of the journey ahead.
Build and test: Let user feedback be your guide
As a product leader, don’t fall into the trap of removing yourself from the execution phase. You don’t have to be the person deploying the new AI model to have an impact. There are many decision points along the way where user-centered input can be invaluable.
Frequently, iterating on AI products boils down to improving data quality. Even without implementing other improvements, providing a model with better training data can have significant benefits. Depending on how your model is currently failing, you can strategically augment its training data. Things to look for include:
- A larger volume of examples
- More accurate labels (if you’re doing supervised machine learning)
- Different data that’s more representative of the production distribution your model will face
Zooming in on LLM applications, it helps to be familiar with these iteration techniques:
- Prompt engineering: Rather than refining the base model, the simplest way to improve an LLM product is by experimenting with different prompts. There’s a lot of nuance here and it’s important to deeply understand how the model is underperforming to nudge it in the right direction.
- Retrieval augmented generation (RAG): With RAG, you can give an LLM access to your own datasets so they have domain-specific knowledge or other custom information. Naturally, a key question here is: what data would the LLM benefit from accessing?
- Model fine-tuning: This is the most involved way to improve an LLM and, unlike the other methods, actually modifies your base LLM. You typically need to provide 50 or more training examples to a model of how to perform a task. The result is a variant of the base model that’s specialized in that task.
Each of these methods is worthy of its own deep dive. For now, the takeaway is that LLM app development is an applied science, not theory. These iterations need to be made with users in mind. So instead of coming up with 50 artificial examples to fine-tune your model, it’s better to use 50 actual examples from your user data and teach the model what it should do.
A single round of prompt engineering or fine-tuning is probably not enough. Throughout the iterations, it’s your responsibility to dogfood the product yourself. Be careful not to let your own experiences bias you; you should test a variety of inputs to validate that your observations affect other users.
For the same reason, it’s in your interest to push for a live A/B experiment sooner rather than later. By measuring your improved LLM’s performance with real users and quantitatively comparing it against the previous version, you can justify launching your model based on more than just “good vibes.”

In my experience at YouTube and Google, I found that interpreting experiment metrics can be one of the most interesting and hardest jobs for a PM. For any given change, you’ll be evaluating up to dozens of metrics. Some will move up, others down, and the picture could look different depending on which user segments you inspect. Some tips:
- Remind yourself of the core reason for the change and predict how you expect the metrics to move before you look at the results.
- Set guardrail metrics and validate that those do not suffer in the pursuit of something else.
- Check key segments (whether demographic or by user intent) to ensure no adverse side effects from what you think is an improvement.
- Quality isn’t the only dimension to optimize for LLMs. Be mindful of cost and latency.
Launch and land: Continuing the product development cycle
An A/B experiment gives you the confidence to fully launch a change, but metrics monitoring doesn’t stop there. Especially for AI products, A/B testing is only an approximation of launching to 100% of users. You may observe material differences in how your model behaves when it ingests the full volume of user inputs and not just a small fraction. There’s an ongoing feedback loop where users will adapt to your model and the model will adapt back—launching to production only amplifies this effect.
Because of these so-called learning effects, it’s worthwhile to track your metrics over a longer time horizon. If you’re using a third-party LLM as your base model, you also can’t guarantee that it’s an identical version to what you were using earlier, which could also cause data to drift.
Instead of immediately launching to 100% of users, it’s good practice to create a holdback group that receives the update after a slight delay. Essentially, you’re running an A/B test again with the proportions flipped. Users with the new feature make up the control group and the minority in the holdback comprise the experiment group. It’s a good sign if you’re able to replicate your original experiment results in the holdback study.
At some point, you’ll decide to end the holdback and move all users to the latest version of your product, completing the product cycle. Now comes the best part—doing it all over again.
Context.ai is your analytics platform for navigating the AI product cycle
There’s another key difference between the conventional software and AI product development cycles: infrastructure and tooling. For a run-of-the-mill mobile app, you can have your pick when it comes to analytics software.
If you’re building an AI product, however, you need an AI-focused analytics solution. Context.ai is that platform, designed specifically for LLM-powered applications. With out-of-the-box support for metrics relevant to LLM teams, Context.ai gives you visibility into how users are behaving (including common conversation topics/intents) and how your AI models are responding. To give it a try, schedule a demo with a member of our team today.