Proving ROI for LLM products


How should you prove the ROI of your LLM product?
This is key to securing resources for your team - and getting everyone promoted
It’s also important to measure so you can identify and fix the weaker areas over time
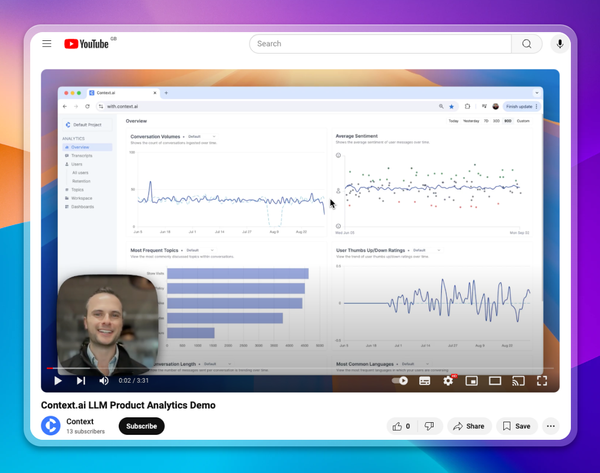
But what does success look like? Product teams use both quantitative and qualitative feedback to answer this question
On the qualitative side it’s worth talking to as many users as you can, and reviewing transcripts and session replays. This isn’t wildly different from a non-LLM based product, but it’s hard to objectively prove ROI from qualitative data.
On the quantitative side things look very different, and vary with the type of LLM product:
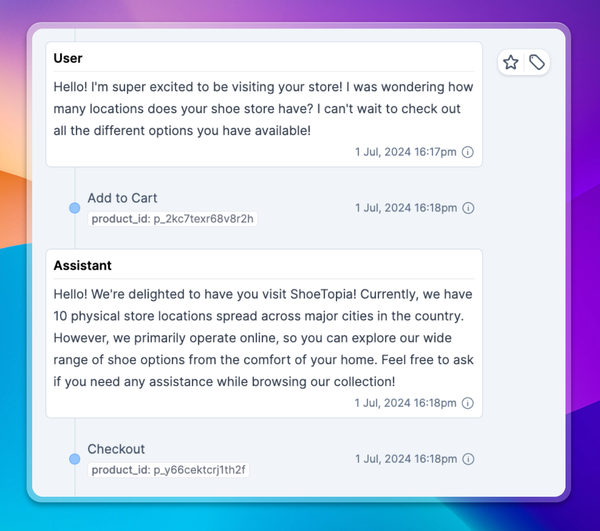
Customer support chatbots goal is to resolve customer issues, and the success metrics should reflect this. We can look at how Intercom measures success for some inspiration. They charge customers of their Fin X chatbot for each customer issue resolved, where the user either confirms their issue is resolved or they exit the chat and don’t return. Resolution rate metrics should be compared against humans to ensure cost savings aren’t coming at the expense of quality. Specific metrics to look at:
- Hard resolution rates - where the user explicitly confirms the issue is resolved
- Soft resolution rates - where the user leaves and doesn’t start another session about the same issue
- CSAT - customer satisfaction in feedback surveys
Consumer entertainment products, such as Character.AI, have very different goals. Instead of working to resolve issues ASAP, you’re looking to keep consumers entertained and engage for long durations. Instead of resolution rates, we look at engagement and retention metrics that would look familiar to a social media product team. Specific metrics to track:
- Average session length
- Time on site
- DAU
B2B copilot or autopilots are different again. Products like Anterior help insurers process claims and authorizations with less human review time. Measuring success for this type of product should be focused on the quality of decisions and cost savings when compared to the legacy process. Metrics to track include:
- Error rate
- Consistency between human and co/autopilot decisions
- Cost savings
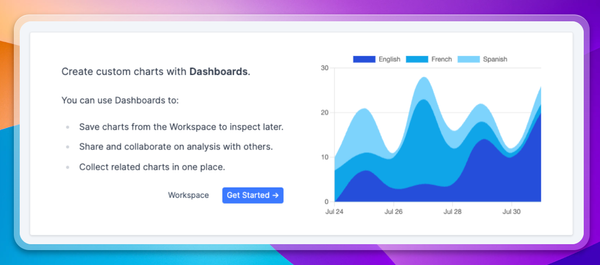
Another significant difference from non-LLM products is the variety of long tail of use cases for any conversational product. To account for this, it's important to segment usage into categories and look at these metrics per category for a granular understanding of performance.