Product Update | February 2024

What’s been cooking at Context.ai?👨🍳
Many more improvements to evals, much-requested analytics features, and some cookbooks too!
Evals now provide Test Set-level comparisons, a side-by-side prompt playground, streaming responses, quality improvements to core CUJs, improved evaluator performance, and support for many more model parameters.
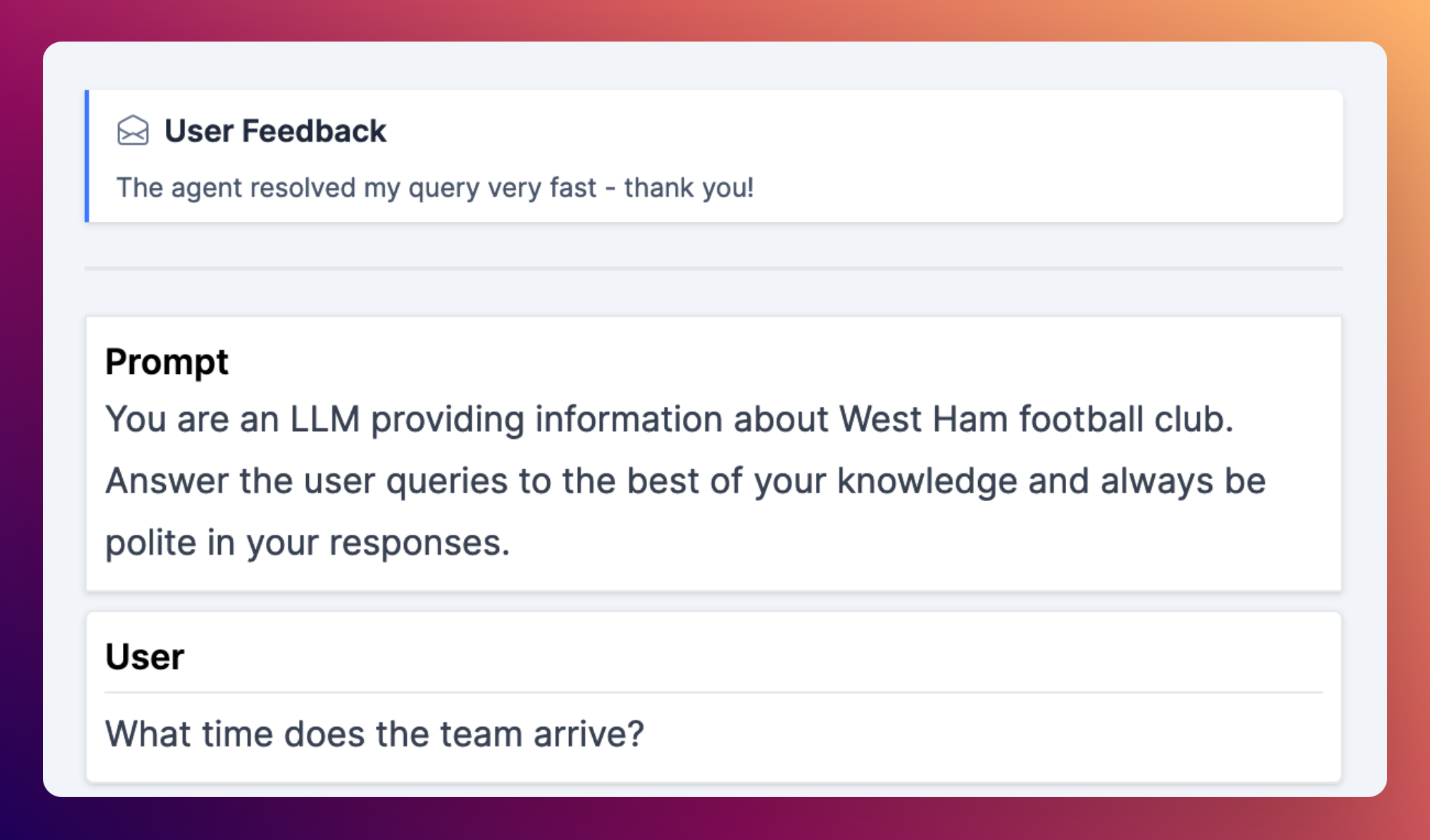
Analytics now supports free text user feedback, so you can track one of the strongest signals of product performance.
This allows builders to monitor the performance of their LLM product before and after release. Get in touch to learn more!
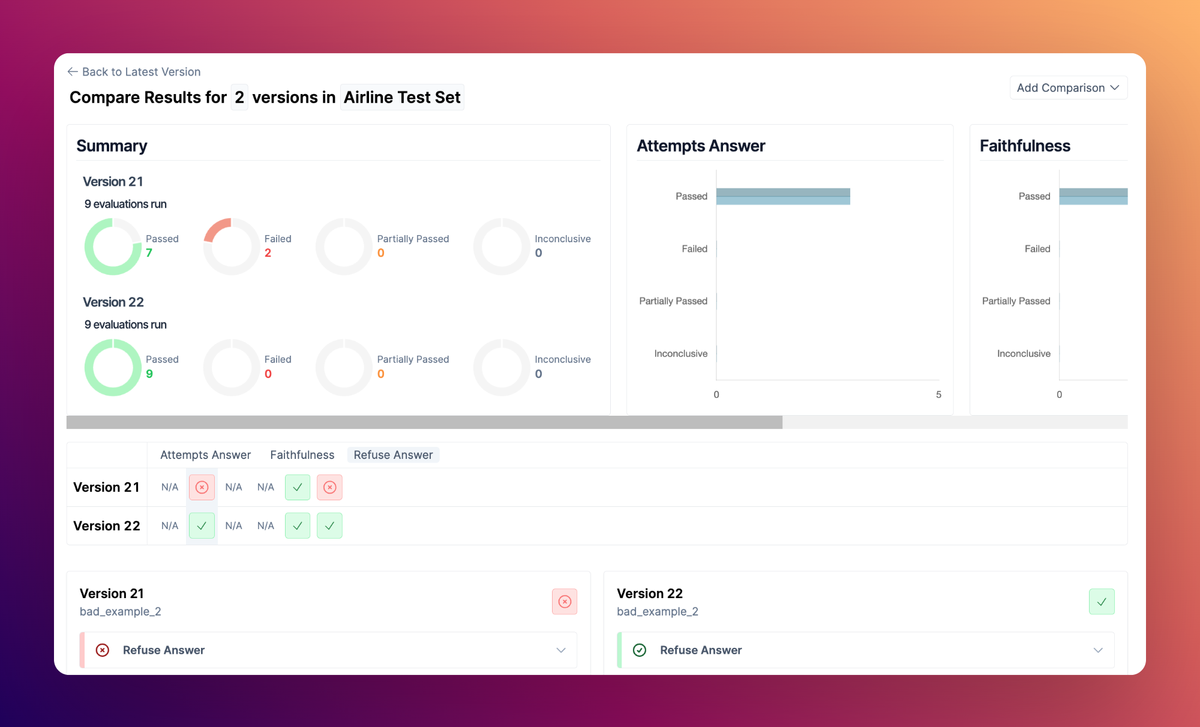
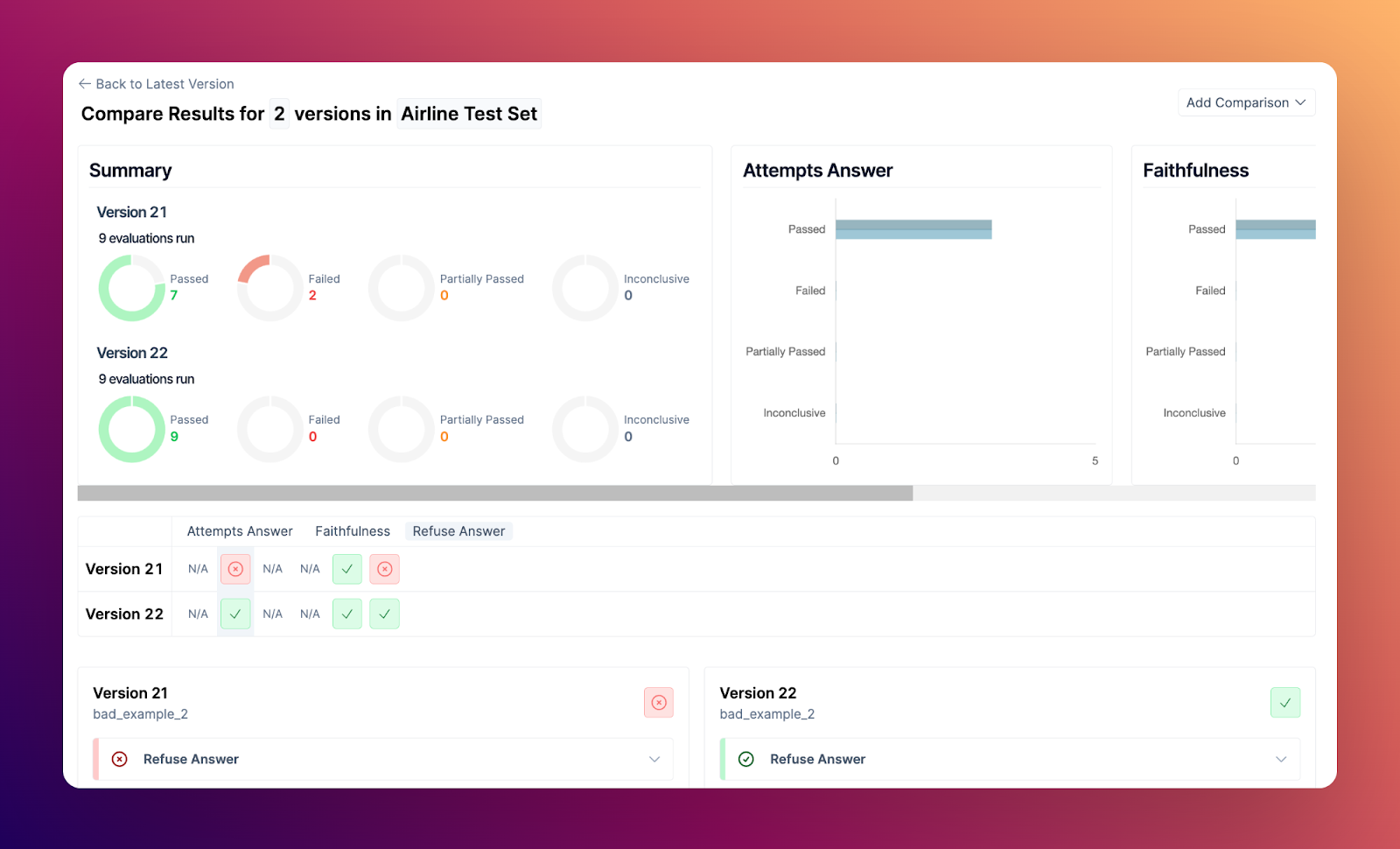
Test Set comparisons
Comparing Test Sets now allows you to easily assess the differences both at the Test Case and also Test Set level. The new Test Set level comparison highlights overall evaluator pass rates for that Test Set, so you don’t need to review every Test Case to judge quality.
Streaming!
Our playgrounds and test sets now stream LLM responses, rather than having to wait for the generation to complete.
Prompt comparison playground
We now support side-by-side comparison of two prompts run across any number of inputs, with immediate streaming responses. This allows prompt engineers to easily compare the impact of prompt updates on many test cases with very rapid iteration times.

Quality improvements on core evals CUJs
We’re continuing to iteratively improve the core evals workflows based on user feedback. Some of the tweaks we’ve made include making edit the default view for not-run test cases, showing tokens and latency in test cases and playgrounds, and allowing edit/duplicate on completed eval runs.
Response ingestion
Evals users can now log pre-generated responses to Context.ai for evaluation. This provides an alternate integration model for evaluation, replacing the need for context windows to be submitted to LLMs by Context.ai. This enables more straightforward evaluation of RAG and other more advanced use cases. Read the docs to get started.
Cookbooks for LangChain and LLamaIndex
We’ve put together cookbooks for evaluating both LangChain and LlamaIndex applications using Context.ai. These walk through the process of setting up Context.ai with LangChain or LlamaIndex to assess the guardrails of an application, ensuring it stays on topic and doesn’t engage with risky inputs.

Improved evaluator accuracy
Our evaluators will now provide evaluation decisions with significantly greater accuracy, and with less chance of getting a different outcome on a re-run. This allows for more consistent evaluation outcomes, and more confidence in the evaluation process. Access the cookbooks in our docs.
Model parameter setting in UI and API
We now support model parameters across all of our supported models from OpenAI, Anthropic, Meta, and Google. We support parameters that vary per-model, but including Temperature, Top P, Top K, Max Tokens, Stop Sequences, Presence Penality and Frequency Penalty. This allows more control over the generation of responses being evaluated, so you can ensure evaluations are consistent with your production generations. See the docs for a full list of supported models and params.

Analytics free text feedback
We now support free text feedback in our analytics product, allowing end user feedback to be logged alongside the transcript. This allows you to learn from end users who provide feedback on your product, which is one of the best signals of user satisfaction available. Free text feedback can be logged via any of our transcripts API ingestion methods.