Our mission at Context.ai is to stop AI builders from flying blind


Our mission at Context.ai is to stop AI builders from flying blind.
AI will have a staggering and positive impact over the next decade. We want to accelerate this transition and the enormous benefits it will bring - from healthcare to productivity. But building high performing, reliable, and safe products is hard, and AI builders need better tooling to stop flying blind.
What do we mean by flying blind? Huge numbers of builders launch LLM products and simply hope everything will go well, usually after completing ad hoc testing and with rudimentary logging in production
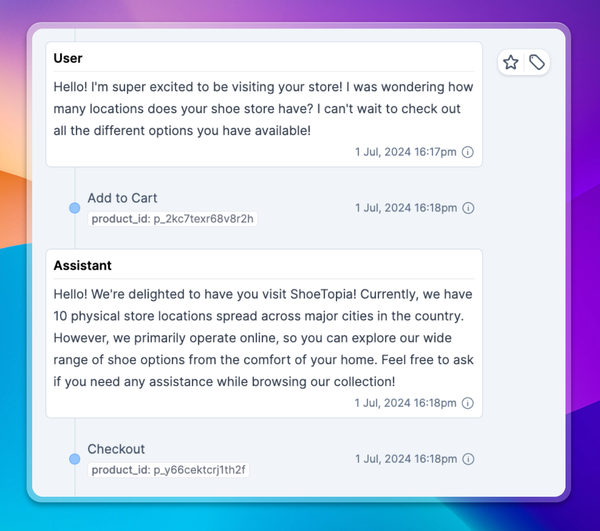
What are the outcomes of flying blind? Poor user experiences, from unaddressed user questions to unreliable response quality, and mishandling of sensitive issues. We’ve seen this increasingly often even among large sophisticated companies
What's the alternative? Companies can make their products better through iteration and experimentation - no matter if they’re a 2 person startup with an unreleased product, or a big tech company with hundreds of millions of DAUs
First, evals allow you to stress test your application before launching or updating it. We fire a large number of simulated queries into your application and grade how the application performs. We assess responses with LLMs, custom code, and manual raters
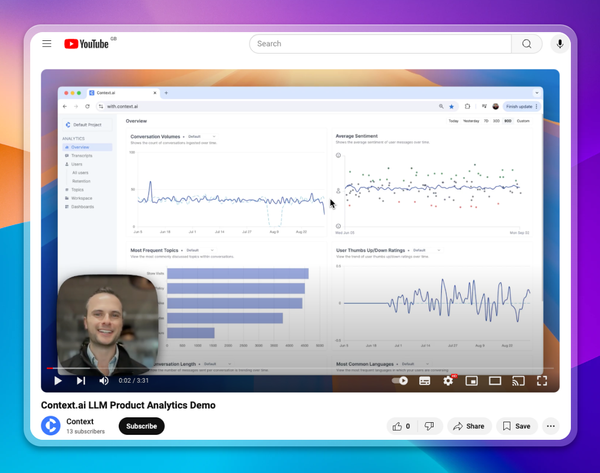
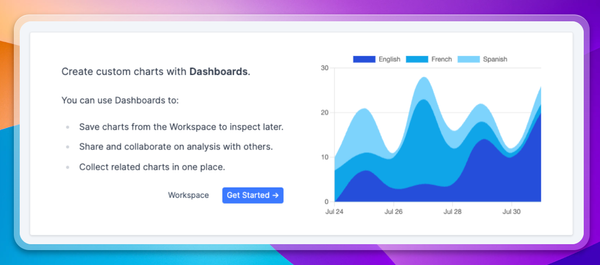
Second, analytics allow you to monitor performance in production, to understand how real users are experiencing your product. We group users by usecase and show success metrics for each usecase, so you can assess where your product is strong, and where it needs improving. This real user data is the ultimate test of your product.
Why combine evals and analytics? You can assess the performance of changes over the full lifecycle in one place, from dev through to production; you can ensure your analytics are predictive of the business outcomes you want with real users, and you can use real user inputs as eval tests
To join our group of happy customers please reach out!