LLM Performance Drifts - And What To Do About Them
Yesterday, researchers at Stanford and Berkeley published a fascinating paper showing that LLM performance drifts over time, including significant worsening.


Yesterday, researchers at Stanford and Berkeley published a fascinating paper showing that LLM performance drifts over time.
I don’t think anyone would be surprised that the OpenAI GPT4 service performs differently to GPT3.5. But even within GPT4 or GPT3.5, performance shifts dramatically, including significant worsening. These changes are opaque, as OpenAI publishes little documentation for users of their services to understand model updates.
Examples of the performance changes identified over just 3 months, from March to June:
- Math problems - “GPT-4’s accuracy [at identifying prime numbers] dropped from 97.6% in March to 2.4% in June”. This is particularly surprising given even a 50/50 guess would be 25x more accurate than the June performance.
- Code generation - “For GPT-4, the percentage of [code] generations that are directly executable dropped from 52.0% in March to 10.0% in June”
- Visual reasoning - “despite better overall performance, GPT-4 in June made mistakes on queries on which it was correct for in March… This underlines the need of fine-grained drift monitoring”
But most concerningly for product builders, the service's handling of sensitive questions significantly worsened. In March GPT3.5 answered only 2% of sensitive questions that should be avoided, whereas in June answered 8% of the questions.
Why might this be happening?
One theory is that OpenAI has made a tradeoff to accept worse quality in return for lower latency in responses, and presumably cost savings too. OpenAI’s VP Product has denied this, but there has been some skepticism in the community. The alternative is that these changes can be explained by model fine tuning and RLHF
As a builder, what should I do about this?
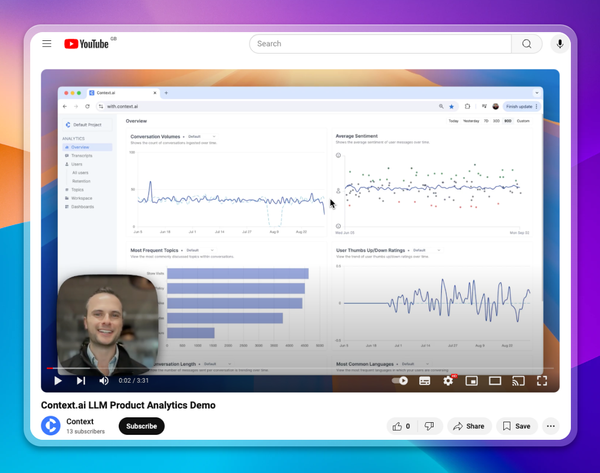
Product developers who rely on these services need to be monitoring their performance with real users, to be confident of product performance and to receive alerts when regressions do occur. The authors agree: “For users or companies who rely on LLM services as a component in their ongoing workflow, we recommend that they should implement similar monitoring analysis as we do here for their applications”
We’ve built Context to help builders track how their product is being used by real people, how their products are performing, and where risky conversation topics are being mishandled. If you’re thinking about the space we’d love to chat!