Generative AI Product Problems #5: Security
What are the security risks of deploying LLMs to production and what can you do to stay prepared?

Don’t let bad actors hijack your LLM.
If you’re going to put your AI assistant out into the world, you need to be confident you aren’t introducing vulnerabilities.
You’ll need to be prepared for a variety of LLM abuse vectors, including:
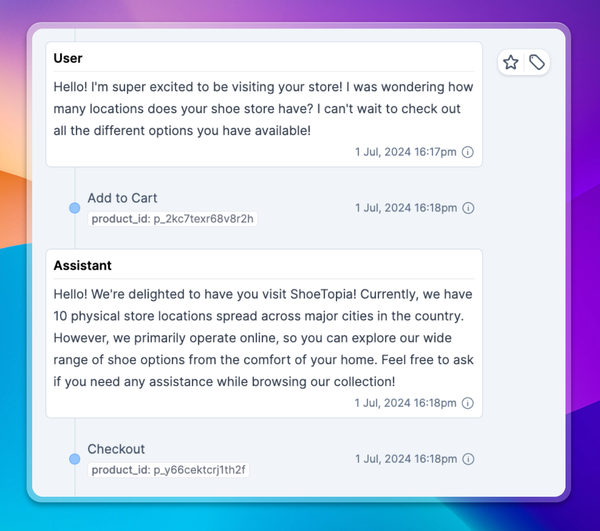
- Prompt injection: An adversary could tell your model to ignore previous instructions and do something else.
- Jailbreaking: Related to prompt injection, jailbreaking involves circumventing an LLM’s safety measures to elicit inappropriate responses.
- Prompt leaking: Somebody could coax an LLM to unveil how exactly it’s been prompted, potentially exposing trade secrets or sensitive information.
- Training data poisoning: Instead of directly attacking your LLM, somebody tampering with its training data or any dataset the model consumes can just as well corrupt its behavior.
- Unauthorized code execution: The more you integrate your LLM with other systems and APIs, the larger the surface area you have to protect. Somebody malicious could try and use your LLM to break into other systems or execute arbitrary code.
So what should you do?
There’s no one-size-fits-all solution, especially because attackers are regularly devising new strategies.
That said, here are some things you can try:
- Filtering: Scan inputs for abusive keywords or suspicious text and filter them out if detected. You can use a conventional ML model or even another LLM.
- Defend your prompts: Incorporate instructions in your prompts that prepare your LLM for malicious inputs. This could be as simple as telling your LLM to ignore further instructions, or something more sophisticated like random sequence enclosure.
- Defend your product: Consider how you’re exposing your LLM to users in the first place. It’s often safer to put an LLM behind the scenes and let it pull specific strings you’ve defined (much like a puppet show). Or, you can try limiting how users provide input to your LLM. Pre-processing their text before giving it to your model could limit vulnerabilities.
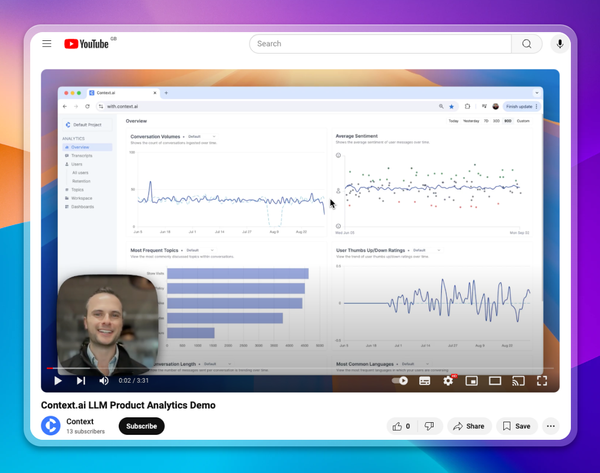
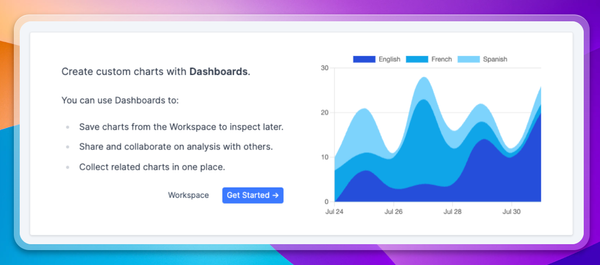
Throughout all of this, it’s important to have a clear understanding of how your users are interacting with your model. Context.ai is the analytics layer that gives you that visibility. With it, you can monitor behavior at the individual user level and put a stop to bad actors.
Request a demo today at context.ai/demo.