Evaluating Multi-Call Chains & Product Update | April 2024

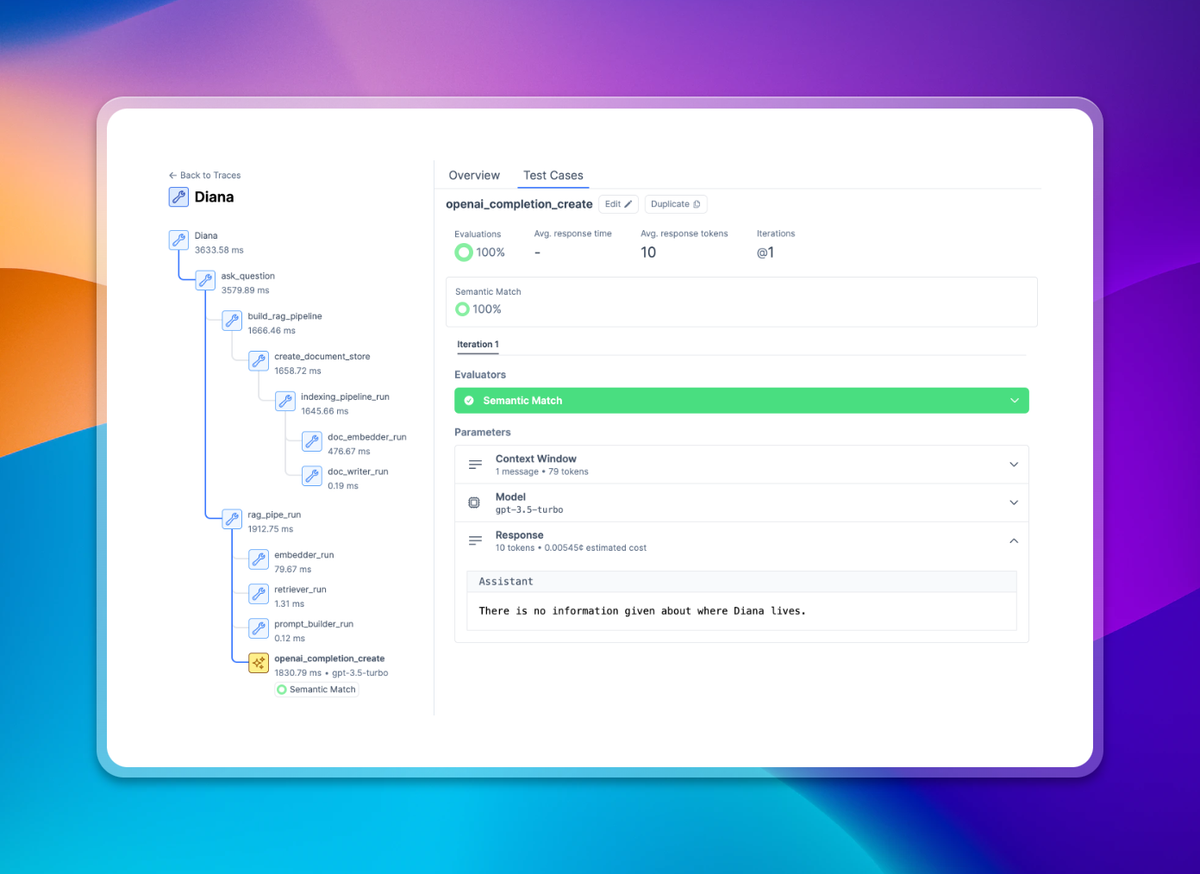
Today we’re launching the ecosystem’s best support for evaluating multi-call chains 🔎⛓️
This allows you to evaluate multi-stage workflows with many calls to LLMs and functions, and you can evaluate these both end-to-end and across any stage of the chain
You can then debug exactly where errors are occuring in the trace using our new visualization
And the best part? It’s fully LangSmith SDK compatible, so it couldn’t be easier to get started evaluating traces of chains
Huge numbers of builders are using multi-stage LLM workflows, but evaluating them is a well-known problem. We’ve spent a ton of time with customers iterating towards a great trace evaluation experience here - and we couldn’t be more excited to share it with the ecosystem
Also this month, we’ve added test case tagging, JSON schema validation evaluators, comparison diff view, many more UX improvements
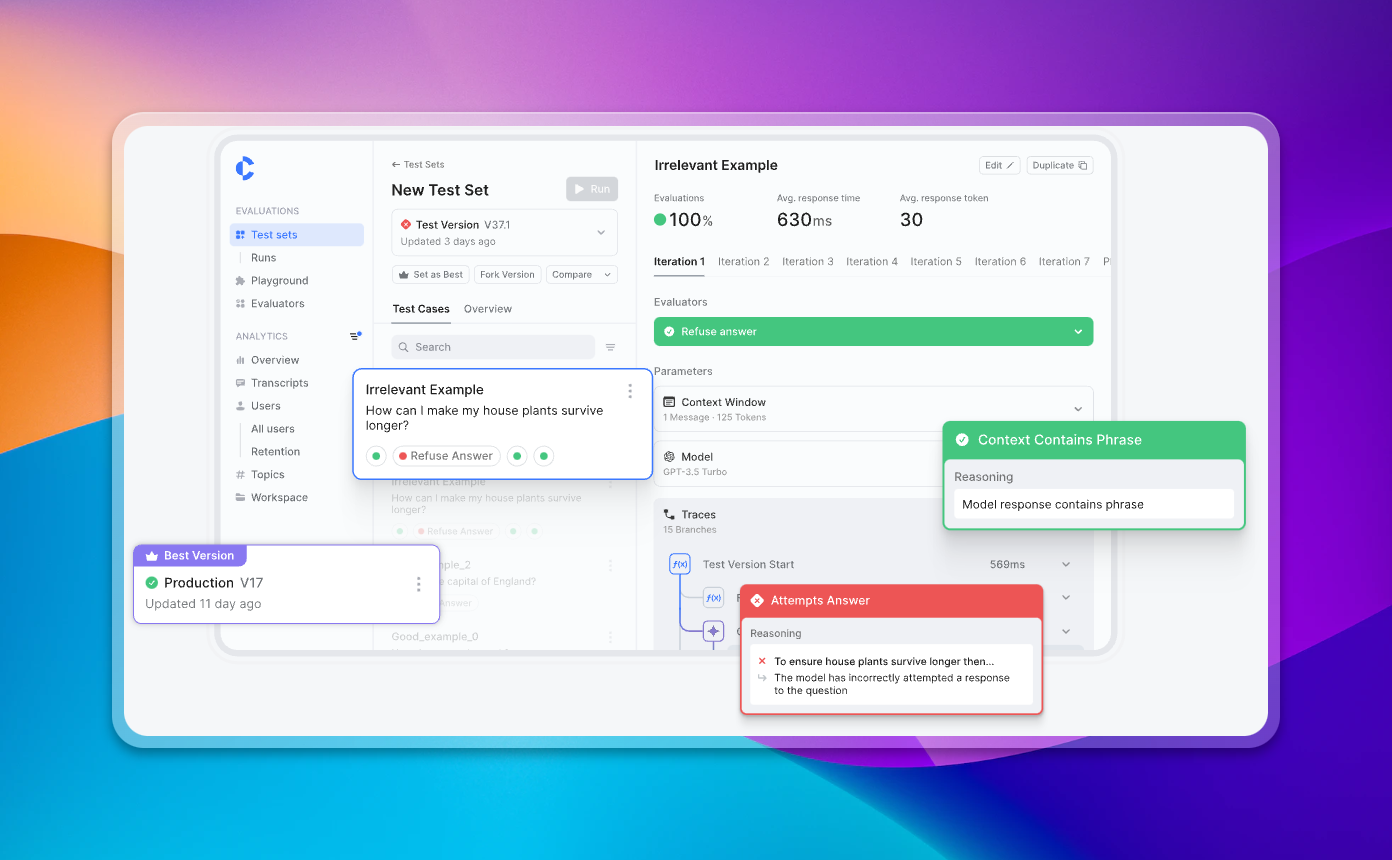
Evaluating Multi-Call Chains!
This is a big one, and a top feature request - we now support tracing, so you can visualize and evaluate multi-call LLM chains.
Uniquely, you can not only visualize multi-call chains, but you can also evaluate them in Context.ai
This enables you to set evaluation checkpoints at various positions in the multi-call chain to systematically evaluate if the chain has gone off the rails
We’re using the LangSmith SDK to ingest traces to make it extremely easy to get started. This is still in beta, but you can onboard to tracing using the docs here.
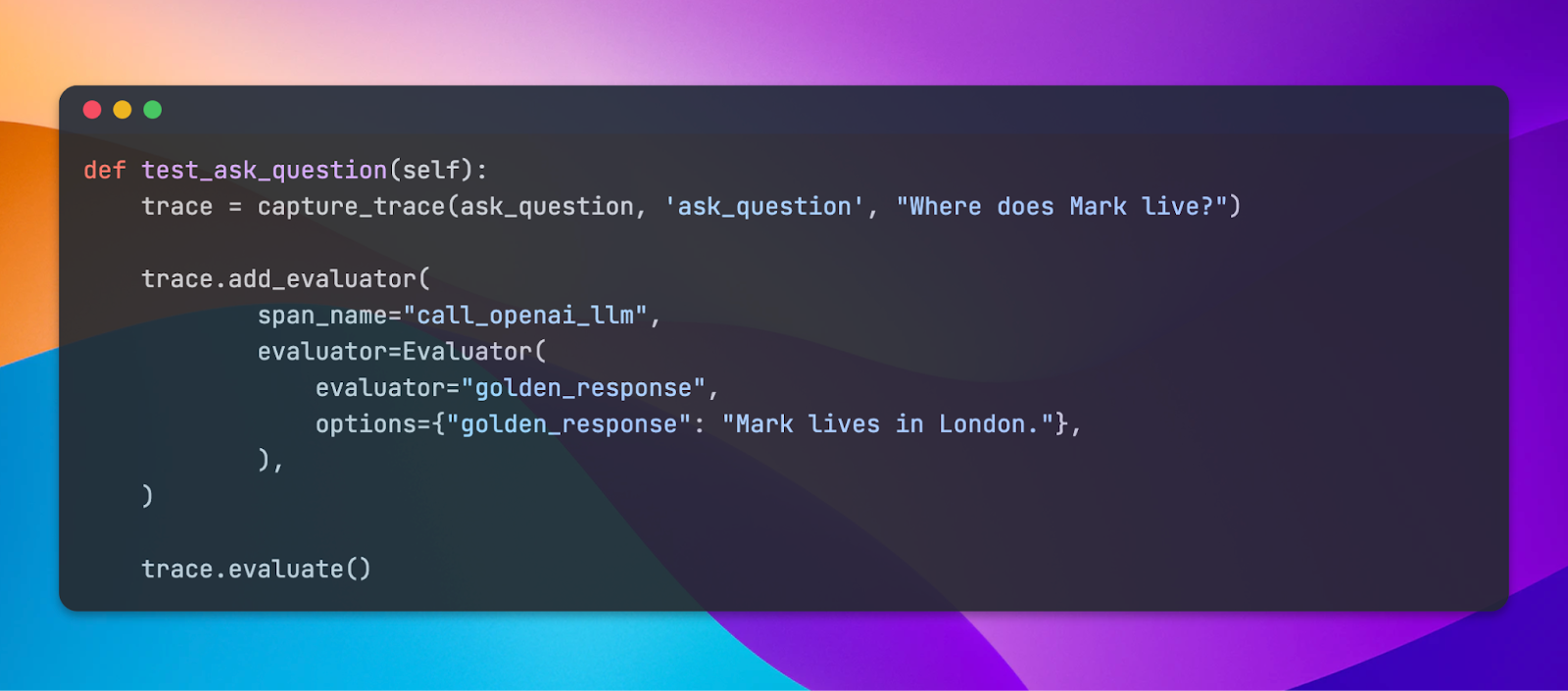
JSON Schema Validation
We now support evaluating responses against a predefined JSON schema. This evaluator accepts an input JSON schema, and then provides a pass/fail outcome indicating if the generated response matches the provided schema. The evaluator additionally provides reasoning for failures, highlighting the cause of the failure, such as a missing field or invalid JSON formatting.
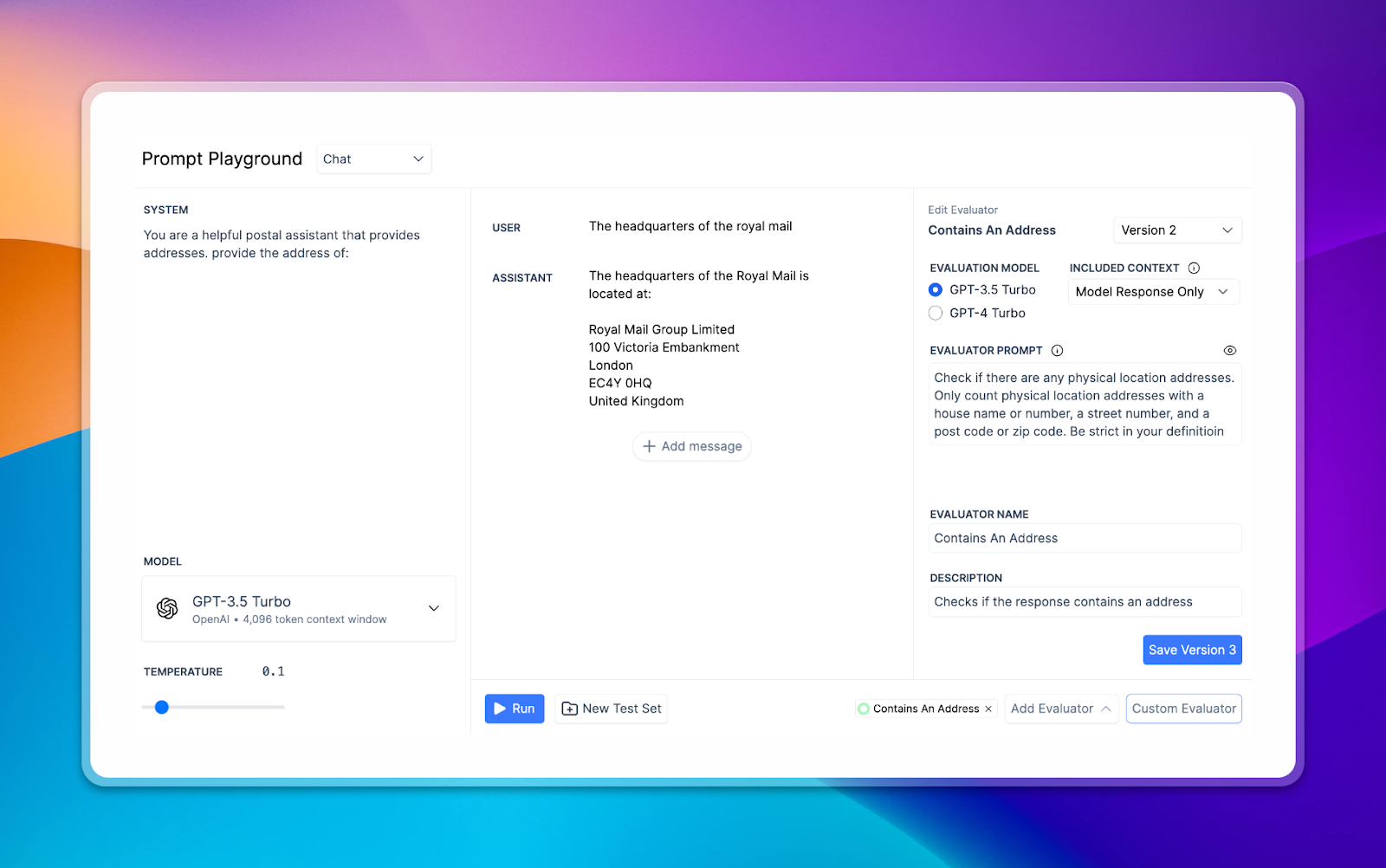
Custom Evaluator Creation Flow
Custom evaluators have a new creation flow, based on the conversation playground. This allows you to evaluate your evaluator, and understand how it will perform before you begin evaluating your test cases with it.
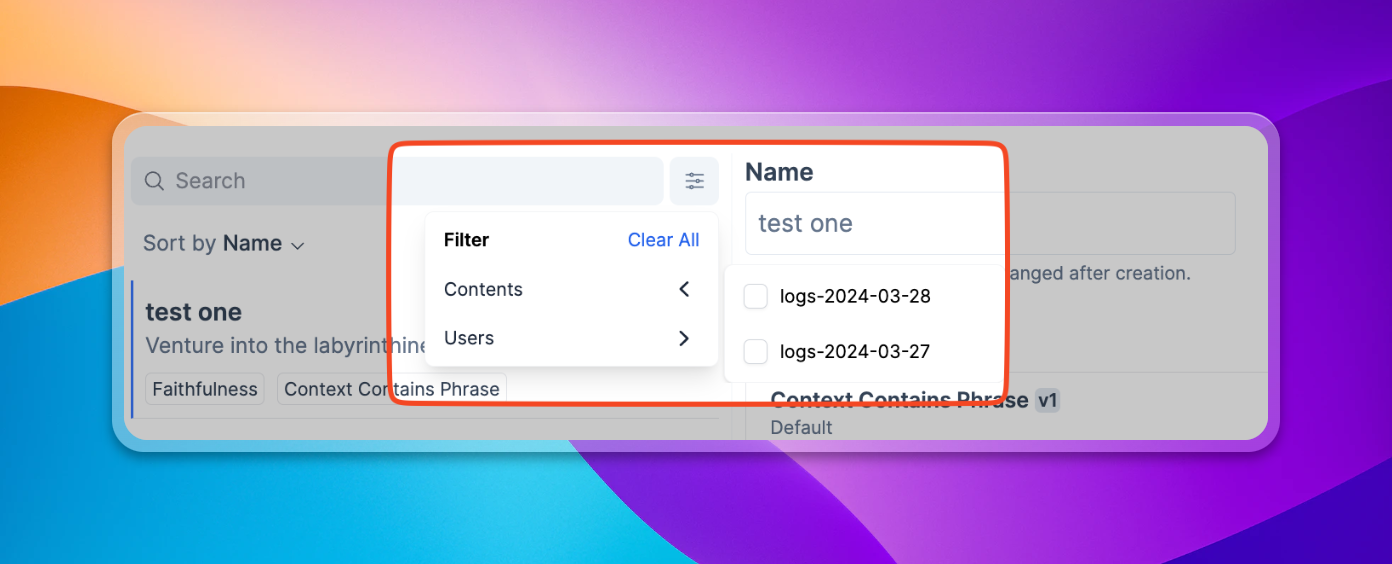
Test Case Tagging
Test cases can now have tags assigned via the API, and these tags allow you to filter your test cases in the Context UI. This has been a common feature request for users with large test sets, and should make them much easier to manage!
Eval Comparison Diff View
Text changes between test cases will now be highlighted in the evals comparison view. This helps you identify the changes to prompts that have caused changes to the test's outcome, and saves you trying to identify changes to long prompts manually.

More UX Improvements
We continue to improve the design of the application! Keep your eyes peeled for usability and visual improvements throughout the product.