Evaluating Changes to your LLM Application – a Tutorial Comparing Gemini Pro to GPT4 Turbo

When building applications using LLMs you have to make a large number of decisions - what model should you use? What system prompt? What model parameters, RAG system, and vector database? Answering those questions when you’re building for the first time is hard, and knowing if you’ve made the best choice for each decision once you’re in production is even harder. What if you could improve the user experience and business outcomes with a different system prompt or model?
In this tutorial we’re going to walk through how to assess the performance impact of changes to your LLM application, showing an example comparing two models - GPT4 Turbo and Gemini Pro.
First, you need to understand the performance impact of a change before you ship it to production. This gives you real time feedback as you experiment with changes, and provides the confidence you need to ship the change to real users. This is the evaluation stage.
Second, you need to test how the change performs with real users, initially as an A/B test, and then as a full rollout
What changes might you be considering?
First, a model provider and model version. Next, you need to pick a system prompt, a choice you’ll likely want to iterate on regularly to improve product performance.
For higher performing or more complex applications you’ll have additional decisions to make, including if you want to use RAG or finetune, and model parameters like temperature.
Assessing performance in development, before you launch a change
After you’ve selected something you want to change, it’s time to begin evaluating its performance. Initially this can be done in an informal manner - running a few queries manually to sense check the quality of the responses. But quickly you’ll want scaled testing, where the change is evaluated against a larger number of queries. This is the evaluation or eval stage, and Context.ai allows you to do this painlessly.
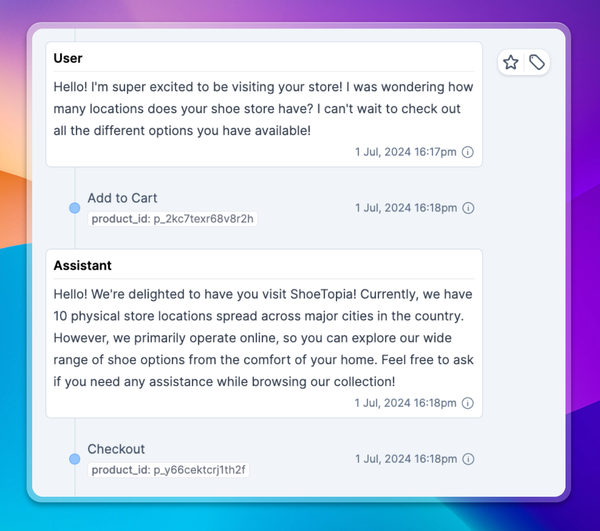
First, you’ll define a set of queries to test your application with. In this example we’ll create a group of test cases for a legal assistant. You can create these cases in our UI, or upload them by API

Now that we’ve defined our test cases, we’ll specify the model we want to run them against - in this first case we’ll use GPT4. We’ll then duplicate the Test Set to create a copy of all our Test Cases, and modify the Cases to use Gemini instead. You could also change the system prompt, or anything else.
Finally, we define evaluators to assess the responses - and there are many options for this. LLM evaluators run prompts to assess the responses, and these can be user defined or selected from our library that address common failure cases, such as hallucination, response refusal, and other common failure cases. Golden response evaluators assess other queries that have exactly correct answers. Now we run both Test Sets, then compare the responses

Now we review the evaluator responses to check for failures, as well as manually review the generated results. This allows us to assess the performance of the different models on these Test Cases, so you can understand their performance impact, and build the confidence you need to launch them to real users. You can use the same methods described here to iterate on your prompts, RAG setup, or any other change to your application.
Assessing performance with real users, after you’ve launched the change
The ultimate measure of success for any product is its impact on real users - and the business outcomes those users drive. This is where the rubber meets the road.
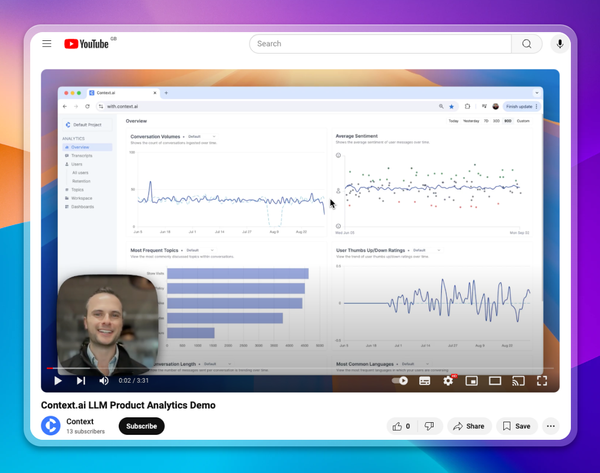
To assess the performance of your product with real users, you should log your transcripts to Context.ai. Context.ai will then tell you how users are interacting with your application - what are they searching for? And we will monitor the performance of the product, broken down by each of the identified use cases - where are user needs being well met? And where is the product falling short?

Ensure the transcripts are annotated with metadata including model names, user IDs, and experiment IDs for the various A/B tests you want to run. This allows you to slice your success metrics. Ensure you’re logging user feedback signals such as thumbs up and down events in the transcript for the best understanding of product performance
Running an A/B test with real users
Changes are best rolled out to real users as A/B tests, and these can be logged in Context.ai.
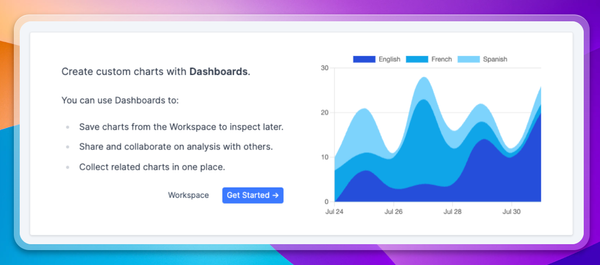
Assign some portion of your users to each experiment arm, and denote this assignment in a custom metadata field. This can be done in a metadata field of ‘experimentID’ defined as ‘1a’ or ‘1b’. Assign each group to receive one variant of your application, and log the resulting production transcripts to Context.ai. You can then compare the performance of each experiment arm, comparing success metrics such as average user rating, average user input sentiment, conversations lengths, and more
Wrapping up
Testing the performance of changes to your application is crucial, both as you take the change through development and then once it’s launched into production
Tooling makes this process much easier - and Context.ai enables you to track the performance of a change through both stages in one place. This ensures your evaluations during the development process are predictive of high product performance with real users, and lets you monitor your changes throughout the development process.