Are your LLM Products Guardrails working?


How do you know if the guardrails on your LLM product are working? 🛡️🎯
Some people wait until they show up in the The New York Times - like McDonald's, Air Canada, or Chevrolet
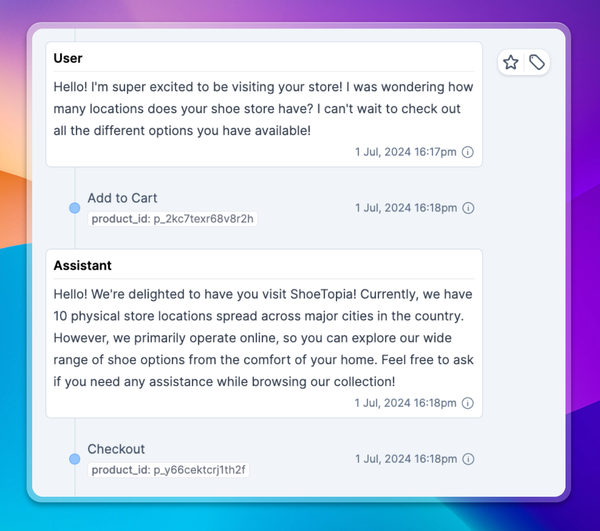
Conversational LLM products are a challenging consumer experience as users can ask an infinite number of inappropriate questions
You need to secure your application against any policy-violating inputs and ensure your product correctly handles them with appropriate answers
We see three stages to this guardrails development process:
1️⃣ Implement guardrails, with a framework like Guardrails AI or Lakera
2️⃣ Evaluate your guardrails before release, with an evaluation tool like LangSmith by LangChain
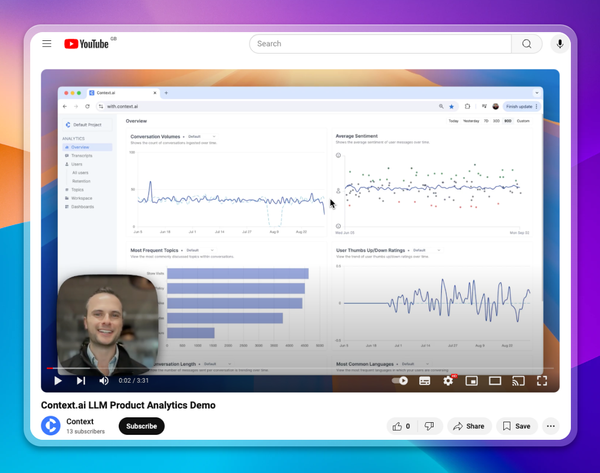
3️⃣ Analyze the guardrails effectiveness in production, with Context.ai
The key metric to track in production is the proportion of conversations that violate your content policies, and how this moves over time.
You should break this down to many categories of sensitive content, from discussion of politics, medical advice, gambling or general off-topic discussion. You additionally want to assess the severity of a violation - is this a borderline case, or a gross violation that justifies banning the user?
How should this be done?
Use classifiers for an initial judgment, then a human review to confirm a sample of negatives. This is particularly important for the period until you’re confident in the automated classification
What should you do with the classification results?
Make the guardrails better! Find problem areas where inappropriate content is getting through, and additionally identify areas where inoffensive content is being incorrectly blocked. Fix those issues, then return to your analytics tool to verify your guardrails have improved.